5. Retrieval-Augmented Generation
Colab Notebook for This Chapter
Naive Chunking:

Late Chunking:
Reciprocal Rank Fusion:
RAG in colab:
–
Langchain Google Web Search
Langchain SQL Query
–
Self-RAG:
Corrective RAG:
Adaptive RAG:
Agentic RAG:
–
Neo4j Cypher:
Graph-RAG:
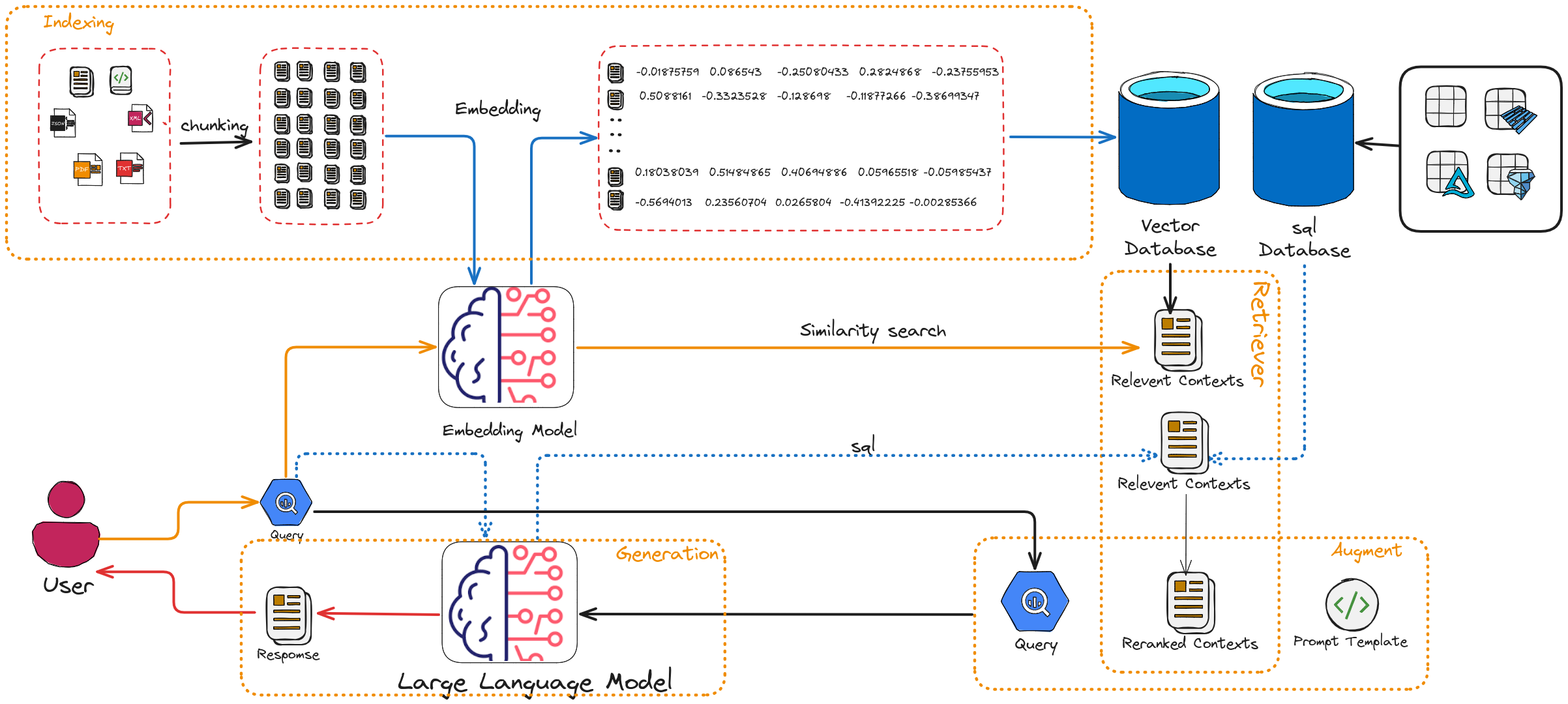
Retrieval-Augmented Generation Diagram
Note
The naive chunking strategy was used in the diagram above. More advanced strategies, such as Late Chunking [lateChunking] (or Chunked Pooling), are discussed later in this chapter.
5.1. Overview
Retrieval-Augmented Generation (RAG) is a framework that enhances large language models (LLMs) by combining their generative capabilities with external knowledge retrieval. The goal of RAG is to improve accuracy, relevance, and factuality by providing the LLM with specific, up-to-date, or domain-specific context from a knowledge base or database during the generation process.
As you can see in Retrieval-Augmented Generation Diagram, the RAG has there main components
Indexer: The indexer processes raw text or other forms of unstructured data and creates an efficient structure (called an index) that allows for fast and accurate retrieval by the retriever when a query is made.
Retriever: Responsible for finding relevant information from an external knowledge source, such as a document database, a vector database, or the web.
Generator: An LLM (like GPT-4, T5, or similar) that uses the retrieved context to generate a response. The model is “augmented” with the retrieved information, which reduces hallucination and enhances factual accuracy.
5.2. Naive RAG
5.2.1. Indexing
The indexing processes raw text or other forms of unstructured data and creates an efficient structure (called an index) that allows for fast and accurate retrieval by the retriever when a query is made.

5.2.1.1. Naive Chunking
Chunking in Retrieval-Augmented Generation (RAG) involves splitting documents or knowledge bases into smaller, manageable pieces (chunks) that can be efficiently retrieved and used by a language model (LLM).
Below are the common chunking strategies used in RAG workflows:
Fixed-Length Chunking
Chunks are created with a predefined, fixed length (e.g., 200 words or 512 tokens).
Simple and easy to implement but might split content mid-sentence or lose semantic coherence.
Example:
def fixed_length_chunking(text, chunk_size=200): words = text.split() return [ " ".join(words[i:i + chunk_size]) for i in range(0, len(words), chunk_size) ] # Example Usage document = "This is a sample document with multiple sentences to demonstrate fixed-length chunking." chunks = fixed_length_chunking(document, chunk_size=10) for idx, chunk in enumerate(chunks): print(f"Chunk {idx + 1}: {chunk}")
Output:
Chunk 1: This is a sample document with multiple sentences to demonstrate
Chunk 2: fixed-length chunking.
Sliding Window Chunking
Creates overlapping chunks to preserve context across splits.
Ensures important information in overlapping regions is retained.
Example:
def sliding_window_chunking(text, chunk_size=100, overlap_size=20): words = text.split() chunks = [] for i in range(0, len(words), chunk_size - overlap_size): chunk = " ".join(words[i:i + chunk_size]) chunks.append(chunk) return chunks # Example Usage document = "This is a sample document with multiple sentences to demonstrate sliding window chunking." chunks = sliding_window_chunking(document, chunk_size=10, overlap_size=3) for idx, chunk in enumerate(chunks): print(f"Chunk {idx + 1}: {chunk}")
- Output:
Chunk 1: This is a sample document with multiple sentences to demonstrate
Chunk 2: with multiple sentences to demonstrate sliding window chunking.
Chunk 3: sliding window chunking.
Semantic Chunking
Splits text based on natural language boundaries such as paragraphs, sentences, or specific delimiters (e.g., headings).
Retains semantic coherence, ideal for better retrieval and generation accuracy.
Example:
import nltk nltk.download('punkt_tab') def semantic_chunking(text, sentence_len=50): sentences = nltk.sent_tokenize(text) chunks = [] chunk = "" for sentence in sentences: if len(chunk.split()) + len(sentence.split()) <= sentence_len: chunk += " " + sentence else: chunks.append(chunk.strip()) chunk = sentence if chunk: chunks.append(chunk.strip()) return chunks # Example Usage document = ("This is a sample document. It is split based on semantic boundaries. " "Each chunk will have coherent meaning for better retrieval.") chunks = semantic_chunking(document, 10) for idx, chunk in enumerate(chunks): print(f"Chunk {idx + 1}: {chunk}")
Output:
Chunk 1: This is a sample document.
Chunk 2: It is split based on semantic boundaries.
Chunk 3: Each chunk will have coherent meaning for better retrieval.
Dynamic Chunking
Adapts chunk sizes based on content properties such as token count, content density, or specific criteria.
Useful when handling diverse document types with varying information density.
Example:
from transformers import AutoTokenizer def dynamic_chunking(text, max_tokens=200, tokenizer_name="bert-base-uncased"): tokenizer = AutoTokenizer.from_pretrained(tokenizer_name) tokens = tokenizer.encode(text, add_special_tokens=False) chunks = [] for i in range(0, len(tokens), max_tokens): chunk = tokens[i:i + max_tokens] chunks.append(tokenizer.decode(chunk)) return chunks # Example Usage document = ("This is a sample document to demonstrate dynamic chunking. " "The tokenizer adapts the chunks based on token limits.") chunks = dynamic_chunking(document, max_tokens=10) for idx, chunk in enumerate(chunks): print(f"Chunk {idx + 1}: {chunk}")
- Output:
Chunk 1: this is a sample document to demonstrate dynamic chunking
Chunk 2: . the tokenizer adapts the chunks based on
Chunk 3: token limits.
Comparison of Strategies
Strategy |
Pros |
Cons |
|---|---|---|
Fixed-Length Chunking |
Simple, fast |
May split text mid-sentence or lose coherence. |
Sliding Window Chunking |
Preserves context |
Overlapping increases redundancy. |
Semantic Chunking |
Coherent chunks |
Requires NLP preprocessing. |
Dynamic Chunking |
Adapts to content |
Computationally intensive. |
Each strategy has its strengths and weaknesses. Select based on the task requirements, context, and available computational resources.
The optimal chunk length depends on the type of content being processed and the intended use case. Below are recommendations for chunk lengths based on different context types, along with their rationale:
Context Type |
Chunk Length (Tokens) |
Rationale |
|---|---|---|
FAQs or Short Texts |
100-200 |
Short enough to handle specific queries. |
Articles or Blog Posts |
300-500 |
Covers logical sections while fitting multiple chunks in the LLM context. |
Research Papers or Reports |
500-700 |
Captures detailed sections like methodology or results. |
Legal or Technical Texts |
200-300 |
Maintains precision due to dense information. |
The valuating Chunking Strategies for Retrieval can be found at: https://research.trychroma.com/evaluating-chunking
5.2.1.2. Late Chunking
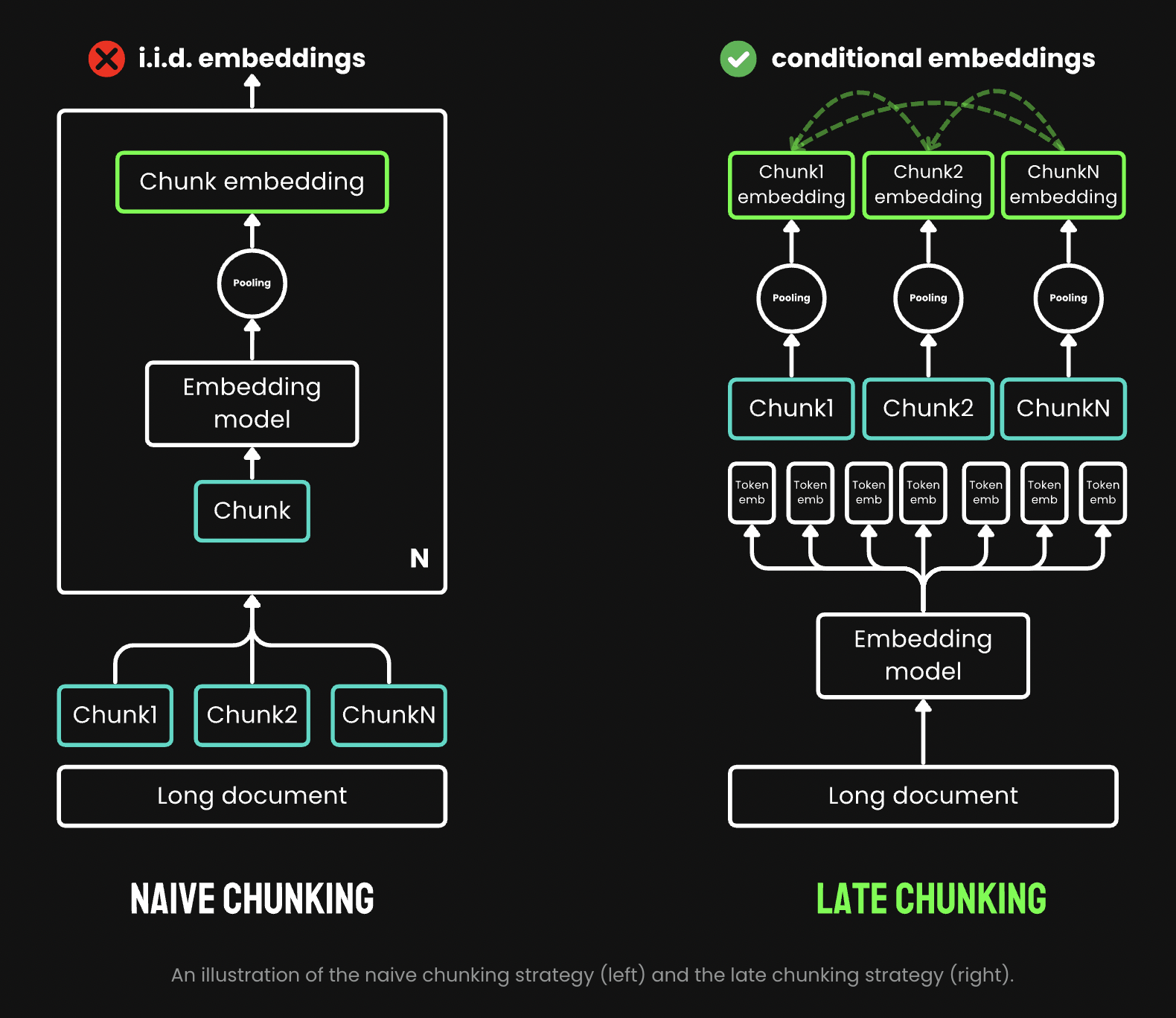
An illustration of the naive chunking strategy (left) and the late chunking strategy (right). (Souce Jina AI)
Late Chunking refers to a strategy in Retrieval-Augmented Generation (RAG) where chunking of data is deferred until query time. Unlike pre-chunking, where documents are split into chunks during preprocessing, late chunking dynamically extracts relevant content when a query is made.
Key Concepts of Late Chunking
Dynamic Chunk Creation:
Full documents or large sections are stored in the vector database.
Relevant chunks are dynamically extracted at query time based on the query and similarity match.
Query-Time Optimization:
The system identifies relevant content using similarity search or semantic analysis.
Only the most relevant content is chunked and passed to the language model.
Reduced Preprocessing Time:
Eliminates extensive preprocessing and fixed chunking during data ingestion.
Higher computational cost occurs during query-time retrieval.
The folloing implementations are from Jina AI, and the copyright belongs to the original author.
def chunk_by_sentences(input_text: str, tokenizer: callable):
"""
Split the input text into sentences using the tokenizer
:param input_text: The text snippet to split into sentences
:param tokenizer: The tokenizer to use
:return: A tuple containing the list of text chunks and their corresponding token spans
"""
inputs = tokenizer(input_text, return_tensors='pt', return_offsets_mapping=True)
punctuation_mark_id = tokenizer.convert_tokens_to_ids('.')
sep_id = tokenizer.convert_tokens_to_ids('[SEP]')
token_offsets = inputs['offset_mapping'][0]
token_ids = inputs['input_ids'][0]
chunk_positions = [
(i, int(start + 1))
for i, (token_id, (start, end)) in enumerate(zip(token_ids, token_offsets))
if token_id == punctuation_mark_id
and (
token_offsets[i + 1][0] - token_offsets[i][1] > 0
or token_ids[i + 1] == sep_id
)
]
chunks = [
input_text[x[1] : y[1]]
for x, y in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)
]
span_annotations = [
(x[0], y[0]) for (x, y) in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)
]
return chunks, span_annotations
def late_chunking(
model_output: 'BatchEncoding', span_annotation: list, max_length=None
):
token_embeddings = model_output[0]
outputs = []
for embeddings, annotations in zip(token_embeddings, span_annotation):
if (
max_length is not None
): # remove annotations which go bejond the max-length of the model
annotations = [
(start, min(end, max_length - 1))
for (start, end) in annotations
if start < (max_length - 1)
]
pooled_embeddings = [
embeddings[start:end].sum(dim=0) / (end - start)
for start, end in annotations
if (end - start) >= 1
]
pooled_embeddings = [
embedding.detach().cpu().numpy() for embedding in pooled_embeddings
]
outputs.append(pooled_embeddings)
return outputs
input_text = "Berlin is the capital and largest city of Germany, both by area and by population. Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. The city is also one of the states of Germany, and is the third smallest state in the country in terms of area."
# determine chunks
chunks, span_annotations = chunk_by_sentences(input_text, tokenizer)
print('Chunks:\n- "' + '"\n- "'.join(chunks) + '"')
# chunk before
embeddings_traditional_chunking = model.encode(chunks)
# chunk afterwards (context-sensitive chunked pooling)
inputs = tokenizer(input_text, return_tensors='pt')
model_output = model(**inputs)
embeddings = late_chunking(model_output, [span_annotations])[0]
import numpy as np
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
berlin_embedding = model.encode('Berlin')
for chunk, new_embedding, trad_embeddings in zip(chunks, embeddings, embeddings_traditional_chunking):
print(f'similarity_new("Berlin", "{chunk}"):', cos_sim(berlin_embedding, new_embedding))
print(f'similarity_trad("Berlin", "{chunk}"):', cos_sim(berlin_embedding, trad_embeddings))
Query |
Chunk |
similarity_new |
similarity_trad |
Berlin |
Berlin is the capital and largest city of Germany, both by area and by population. |
0.849546 |
0.8486219 |
Berlin |
Its more than 3.85 million inhabitants make it the European Union’s most populous city, as measured by population within city limits.” |
0.82489026 |
0.70843387 |
Berlin |
The city is also one of the states of Germany, and is the third smallest state in the country in terms of area.” |
0.8498009 |
0.75345534 |
5.2.1.3. Types of Indexing
The embedding methods we introduced in Chapter Word and Sentence Embedding can be applied here to convert each chunk into embeddings and create indexing. These indexings(embeddings) will be used to retrieve relevant documents or information.
Sparse Indexing:
Uses traditional keyword-based methods (e.g., TF-IDF, BM25). Index stores the frequency of terms and their associations with documents.
Advantages:Easy to understand and deploy and works well for exact matches or keyword-heavy queries.
Disadvantages: Struggles with semantic understanding or paraphrased queries.
Dense Indexing:
Uses vector embeddings to capture semantic meaning. Documents are represented as vectors in a high-dimensional space, enabling similarity search.
Advantages: Excellent for semantic search, handling synonyms, and paraphrasing.
Disadvantages: Requires more computational resources for storage and retrieval.
Hybrid Indexing:
Combines sparse and dense indexing for more robust search capabilities. For example, Elasticsearch can integrate BM25 with vector search.
5.2.1.4. Vector Database
Vector databases are essential for Retrieval-Augmented Generation (RAG) systems, enabling efficient similarity search on dense vector embeddings. Below is a comprehensive overview of popular vector databases for RAG workflows:
FAISS (Facebook AI Similarity Search)
Description: - An open-source library developed by Facebook AI for efficient similarity search and clustering of dense vectors.
Features: - High performance and scalability. - Supports various indexing methods like
Flat,IVF, andHNSW. - GPU acceleration for faster searches.Use Cases: - Research and prototyping. - Scenarios requiring custom implementations.
Limitations: - File-based storage; lacks a built-in distributed or managed cloud solution.
Official Website: FAISS GitHub
Pinecone
Description: - A fully managed vector database designed for production-scale workloads.
Features: - Scalable and serverless architecture. - Automatic scaling and optimization of indexes. - Hybrid search (combining vector and keyword search). - Integrates with popular frameworks like LangChain and OpenAI.
Use Cases: - Enterprise-grade applications. - Handling large datasets with minimal operational overhead.
Official Website: Pinecone
Weaviate
Description: - An open-source vector search engine with a strong focus on modularity and customization.
Features: - Supports hybrid search and symbolic reasoning. - Schema-based data organization. - Plugin support for pre-built and custom vectorization modules. - Cloud-managed and self-hosted options.
Use Cases: - Applications requiring hybrid search capabilities. - Knowledge graphs and semantically rich data.
Official Website: Weaviate
Milvus
Description: - An open-source, high-performance vector database designed for similarity search on large datasets.
Features: - Distributed and scalable architecture. - Integration with FAISS, Annoy, and HNSW indexing techniques. - Built-in support for time travel queries (searching historical data).
Use Cases: - Video, audio, and image search applications. - Large-scale datasets requiring real-time indexing and retrieval.
Official Website: Milvus
Qdrant
Description: - An open-source, lightweight vector database focused on ease of use and modern developer needs.
Features: - Supports HNSW for efficient vector search. - Advanced filtering capabilities for combining metadata with vector queries. - REST and gRPC APIs for integration. - Docker-ready deployment.
Use Cases: - Scenarios requiring metadata-rich search. - Lightweight deployments with simplicity in mind.
Official Website: Qdrant
Redis (with Vector Similarity Search Module)
Description: - A popular in-memory database with a module for vector similarity search.
Features: - Combines vector search with traditional key-value storage. - Supports hybrid search and metadata filtering. - High throughput and low latency due to in-memory architecture.
Use Cases: - Applications requiring real-time, low-latency search. - Integrating vector search with existing Redis-based systems.
Official Website: Redis Vector Search
Zilliz
Description: - A cloud-native vector database built on Milvus for scalable and managed vector storage.
Features: - Fully managed service for vector data. - Seamless scaling and distributed indexing. - Integration with machine learning pipelines.
Use Cases: - Large-scale enterprise deployments. - Cloud-native solutions with minimal infrastructure management.
Official Website: Zilliz
Vespa
Description: - A real-time serving engine supporting vector and hybrid search.
Features: - Combines vector search with advanced ranking and filtering. - Scales to large datasets with support for distributed clusters. - Powerful query configuration options.
Use Cases: - E-commerce and recommendation systems. - Applications with complex ranking requirements.
Official Website: Vespa
Chroma
Description: - An open-source, user-friendly vector database built for LLMs and embedding-based applications.
Features: - Designed specifically for RAG workflows. - Simple Python API for seamless integration with AI models. - Efficient and customizable vector storage for embedding data.
Use Cases: - Prototyping and experimentation for LLM-based applications. - Lightweight deployments for small to medium-scale RAG systems.
Official Website: Chroma
Comparison of Vector Databases:
Database |
Open Source |
Managed Service |
Key Features |
Best For |
|---|---|---|---|---|
FAISS |
Yes |
No |
High performance, GPU acceleration |
Research, prototyping |
Pinecone |
No |
Yes |
Serverless, automatic scaling |
Enterprise-scale applications |
Weaviate |
Yes |
Yes |
Hybrid search, modularity |
Knowledge graphs |
Milvus |
Yes |
No |
Distributed, high performance |
Large-scale datasets |
Qdrant |
Yes |
No |
Lightweight, metadata filtering |
Small to medium-scale apps |
Redis |
No |
Yes |
In-memory performance, hybrid search |
Real-time apps |
Zilliz |
No |
Yes |
Fully managed Milvus |
Enterprise cloud solutions |
Vespa |
Yes |
No |
Hybrid search, real-time ranking |
E-commerce, recommendations |
Chroma |
Yes |
No |
LLM-focused, simple API |
Prototyping, lightweight apps |
Choosing a Vector Database
For Research or Small Projects: FAISS, Qdrant, Milvus, or Chroma.
For Enterprise or Cloud-Native Workflows: Pinecone, Zilliz, or Weaviate.
For Real-Time Use Cases: Redis or Vespa.
Each database has unique strengths and is suited for specific RAG use cases. The choice depends on scalability, integration needs, and budget.
5.2.2. Retrieval
The retriever selects “chunks” of text (e.g., paragraphs or sections) relevant to the user’s query.
5.2.2.1. Common retrieval methods
Sparse Vector Search: Traditional keyword-based retrieval (e.g., TF-IDF, BM25).
Dense Vector Search: Vector-based search using embeddings e.g.
Approximate Nearest Neighbor (ANN) Search:
HNSW (Hierarchical Navigable Small World): Graph-based approach
IVF (Inverted File Index): Clusters embeddings into groups and searches within relevant clusters.
Exact Nearest Neighbor Search: Computes similarities exhaustively for all vectors in the corpus
Hybrid Search (Fig Reciprocal Rank Fusion): the combination of Sparse and Dense vector search.
Note
BM25 (Best Matching 25) is a popular ranking function used by search engines and information retrieval systems to rank documents based on their relevance to a given query. It belongs to the family of bag-of-words retrieval models and is an enhancement of the TF-IDF (Term Frequency-Inverse Document Frequency) approach.
Key Features of BM25
Relevance Scoring:
BM25 scores documents by measuring how well the query terms match the terms in the document.
It incorporates term frequency, inverse document frequency, and document length normalization.
Formula:
The BM25 score for a document
Dgiven a queryQis calculated as:\[\text{BM25}(D, Q) = \sum_{t \in Q} \text{IDF}(t) \cdot \frac{\text{f}(t, D) \cdot (k_1 + 1)}{\text{f}(t, D) + k_1 \cdot (1 - b + b \cdot \frac{|D|}{\text{avgdl}})}\]Where: -
t: Query term. -f(t, D): Frequency of termtin documentD. -|D|: Length of documentD(number of terms). -avgdl: Average document length in the corpus. -k1: Tuning parameter that controls term frequency saturation (usually set between 1.2 and 2.0). -b: Tuning parameter that controls length normalization (usually set to 0.75). -IDF(t): Inverse Document Frequency of termt, calculated as:\[\text{IDF}(t) = \log \frac{N - n_t + 0.5}{n_t + 0.5}\]Where
Nis the total number of documents in the corpus, andn_tis the number of documents containingt.Improvements Over TF-IDF:
Document Length Normalization: BM25 adjusts for the length of documents, addressing the bias of TF-IDF toward longer documents.
Saturation of Term Frequency: BM25 avoids the overemphasis of excessively high term frequencies by using a non-linear saturation function controlled by
k1.
Applications:
Information Retrieval: Ranking search results by relevance.
Question Answering: Identifying relevant documents or passages for a query.
Document Matching: Comparing similarities between textual content.
Limitations:
BM25 does not consider semantic meanings or relationships between words, relying solely on exact term matches.
It may struggle with queries or documents that require contextual understanding.
Summary of Common Algorithms:
Metric/Algorithm |
Purpose |
Common Use |
|---|---|---|
TF-IDF |
Keyword matching with term weighting. |
Effective for small-scale or structured corpora. |
BM25 |
Advanced keyword matching with term frequency saturation and document length normalization. |
Widely used in sparse search; default in tools like Elasticsearch and Solr. |
Cosine Similarity |
Measures orientation (ignores magnitude). |
Widely used; works well with normalized vectors. |
Dot Product Similarity |
Measures magnitude and direction. |
Preferred in embeddings like OpenAI’s models. |
Euclidean Distance |
Measures absolute distance between vectors. |
Less common but used in some specific cases. |
HNSW (ANN) |
Fast and scalable nearest neighbor search. |
Default for large-scale systems (e.g., FAISS). |
IVF (ANN) |
Efficient clustering-based search. |
Often combined with product quantization. |
5.2.2.2. Reciprocal Rank Fusion
Reciprocal Rank Fusion (RRF) is a ranking technique commonly used in information retrieval and ensemble learning. Although it is not specific to large language models (LLMs), it can be applied to scenarios where multiple ranking systems (or scoring mechanisms) produce different rankings, and you want to combine them into a single, unified ranking.
- The reciprocal rank of an item in a ranked list is calculated as \(\frac{1}{k+r}\), where
r is the rank of the item (1 for the top rank, 2 for the second rank, etc.).
k is a small constant (often set to 60 or another fixed value) to control how much weight is given to higher ranks.
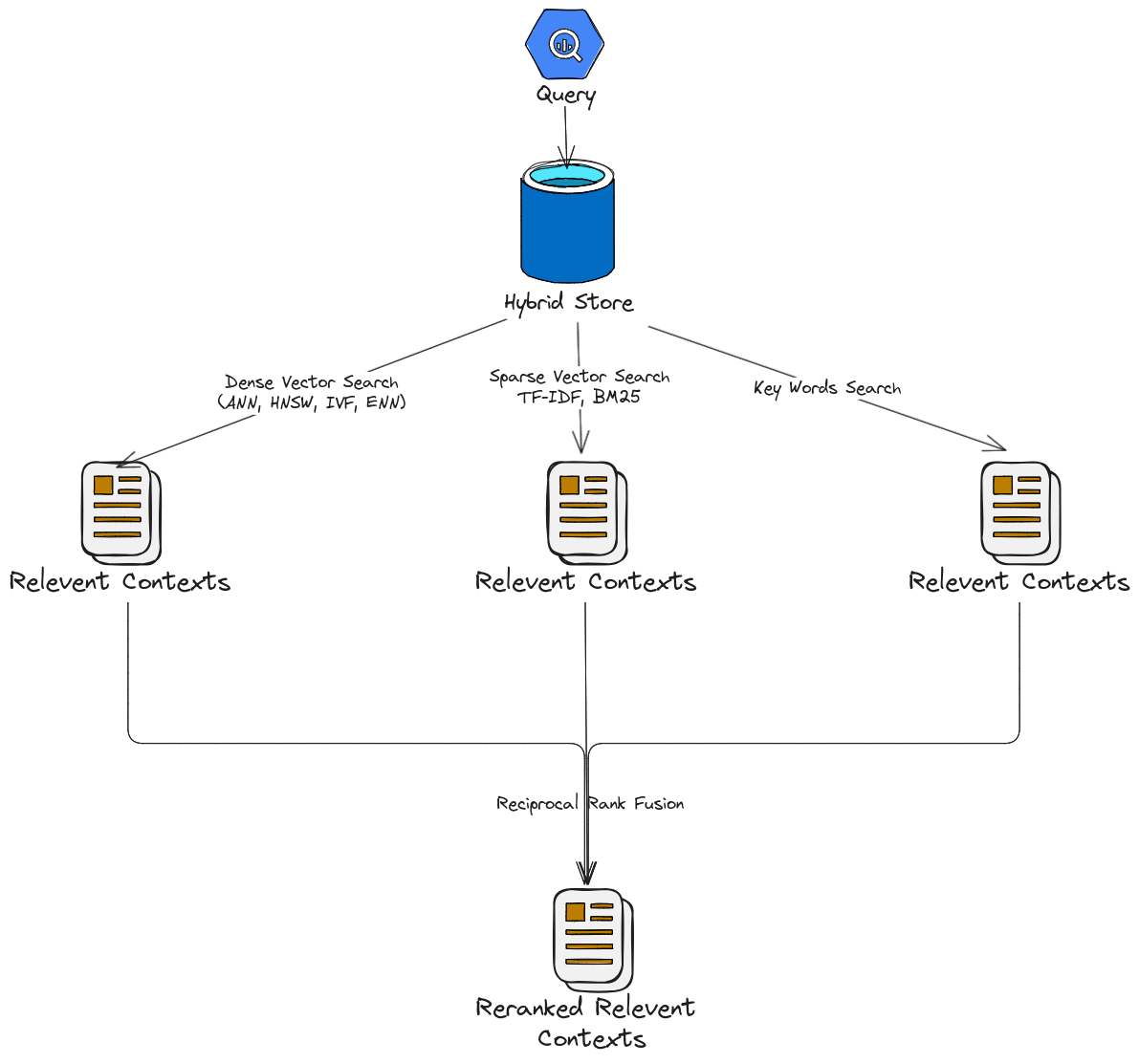
Reciprocal Rank Fusion
Example:
Suppose two retrieval models give ranked lists for query responses:
Model 1 ranks documents as: [A,B,C,D]
Model 2 ranks documents as: [B,A,D,C]
RRF combines these rankings by assigning each document a combined score:
Document A: \(\frac{1}{60+1} +\frac{1}{60+2}=0.03252247488101534\)
Document B: \(\frac{1}{60+2} +\frac{1}{60+1}=0.03252247488101534\)
Document C: \(\frac{1}{60+3} +\frac{1}{60+4}=0.03149801587301587\)
Document D: \(\frac{1}{60+4} +\frac{1}{60+3}=0.03149801587301587\)
from collections import defaultdict
def reciprocal_rank_fusion(ranked_results: list[list], k=60):
"""
Fuse rank from multiple retrieval systems using Reciprocal Rank Fusion.
Args:
ranked_results: Ranked results from different retrieval system.
k (int): A constant used in the RRF formula (default is 60).
Returns:
Tuple of list of sorted documents by score and sorted documents
"""
# Dictionary to store RRF mapping
rrf_map = defaultdict(float)
# Calculate RRF score for each result in each list
for rank_list in ranked_results:
for rank, item in enumerate(rank_list, 1):
rrf_map[item] += 1 / (rank + k)
# Sort items based on their RRF scores in descending order
sorted_items = sorted(rrf_map.items(), key=lambda x: x[1], reverse=True)
# Return tuple of list of sorted documents by score and sorted documents
return sorted_items, [item for item, score in sorted_items]
# Example ranked lists from different sources
ranked_a = ['A', 'B', 'C', 'D']
ranked_b = ['B', 'A', 'D', 'C']
# Combine the lists using RRF
combined_list = reciprocal_rank_fusion([ranked_a, ranked_b])
print(combined_list)
([('A', 0.03252247488101534), ('B', 0.03252247488101534), ('C', 0.03149801587301587), ('D', 0.03149801587301587)], ['A', 'B', 'C', 'D'])
5.2.3. Generation
Finally, the retrieved relevant information will be feed back into the LLMs to generate responses.

Note
In the remainder of this implementation, we will use the following components:
Vector database:
ChromaEmbedding model:
BAAI/bge-m3LLM:
mistralWeb search engine:
Google
# Load models
from langchain_ollama import OllamaEmbeddings
from langchain_ollama.llms import OllamaLLM
## embedding model
embedding = OllamaEmbeddings(model="bge-m3")
## LLM
llm = OllamaLLM(temperature=0.0, model='mistral', format='json')
# Indexing
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_ollama import OllamaEmbeddings # Import OllamaEmbeddings instead
urls = [
"https://python.langchain.com/v0.1/docs/get_started/introduction/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OllamaEmbeddings(model="bge-m3"),
)
# Retriever
retriever = vectorstore.as_retriever(k=5)
# Generation
questions = [
"what is LangChain?",
]
for question in questions:
retrieved_context = retriever.invoke(question)
formatted_prompt = prompt.format(context=retrieved_context, question=question)
response_from_model = model.invoke(formatted_prompt)
parsed_response = parser.parse(response_from_model)
print(f"Question: {question}")
print(f"Answer: {parsed_response}")
print()
Answer: {
"answer": "LangChain refers to chains, agents, and retrieval strategies that make up an application's cognitive architecture."
}
5.3. Self-RAG
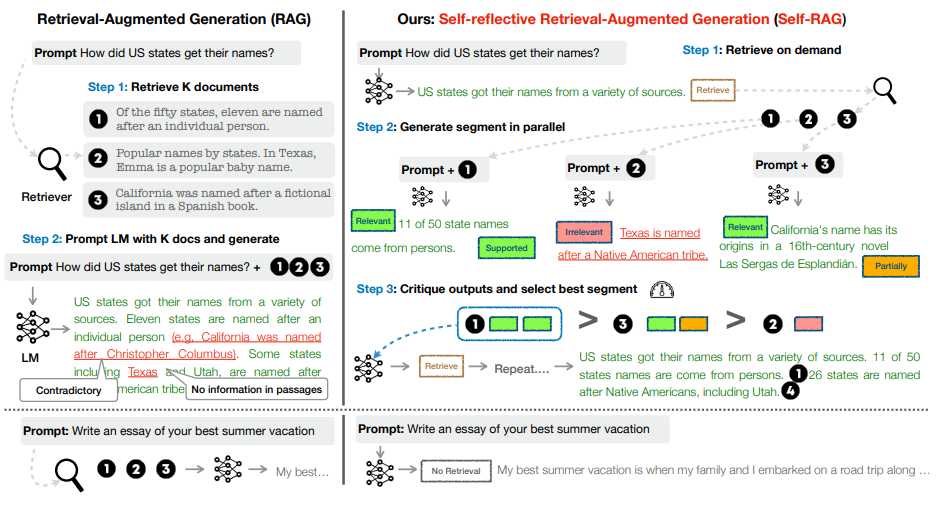
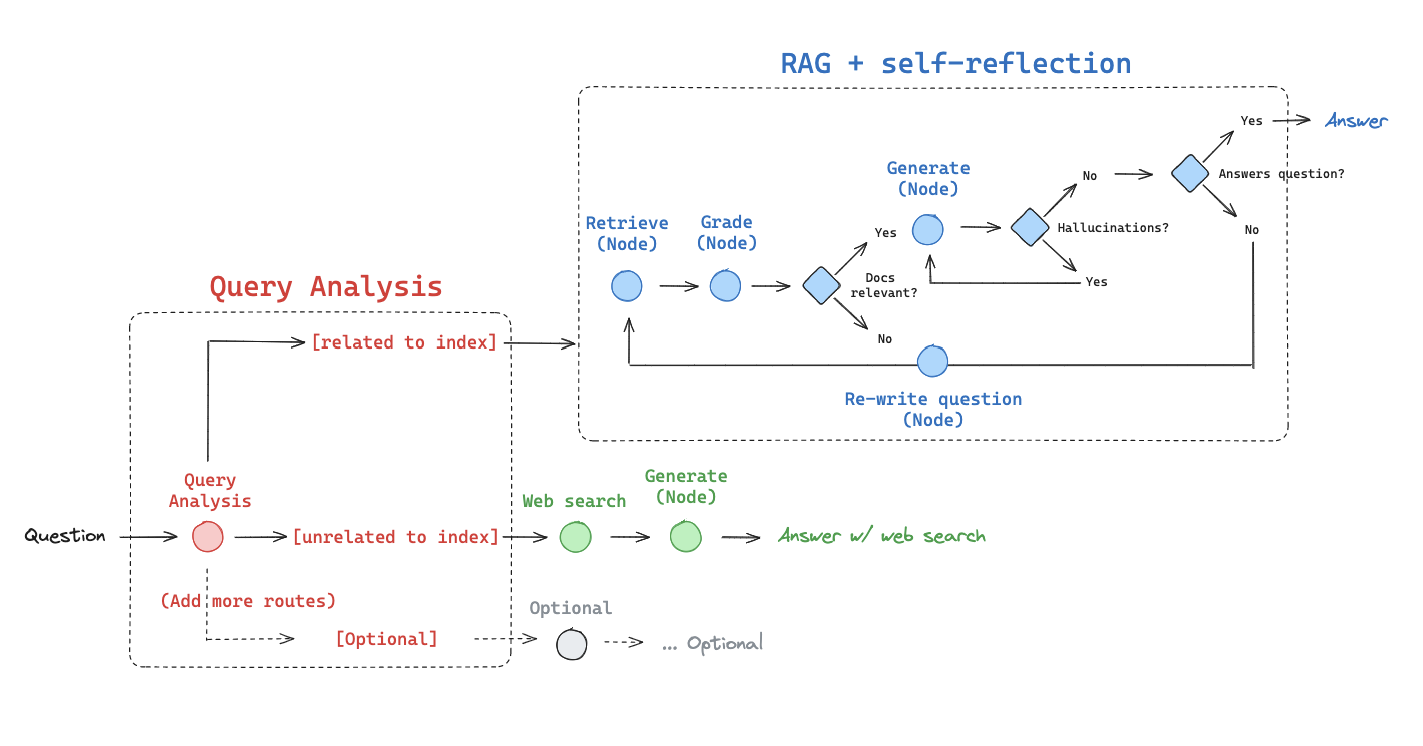
In the paper [selfRAG], Four types decisions are made:
Should I retrieve from retriever, R
Input: - x (question) - OR x (question), y (generation)
Description: Decides when to retrieve D chunks with R.
Output: - yes - no - continue
Are the retrieved passages D relevant to the question x
Input: - (x (question), d (chunk)) for d in D
Description: Determines if d provides useful information to solve x.
Output: - relevant - irrelevant
Are the LLM generations from each chunk in D relevant to the chunk (hallucinations, etc.)
Input: - x (question), d (chunk), y (generation) for d in D
Description: Verifies if all statements in y (generation) are supported by d.
Output: - fully supported - partially supported - no support
Is the LLM generation from each chunk in D a useful response to x (question)
Input: - x (question), y (generation) for d in D
Description: Assesses if y (generation) is a useful response to x (question).
Output: - {5, 4, 3, 2, 1}
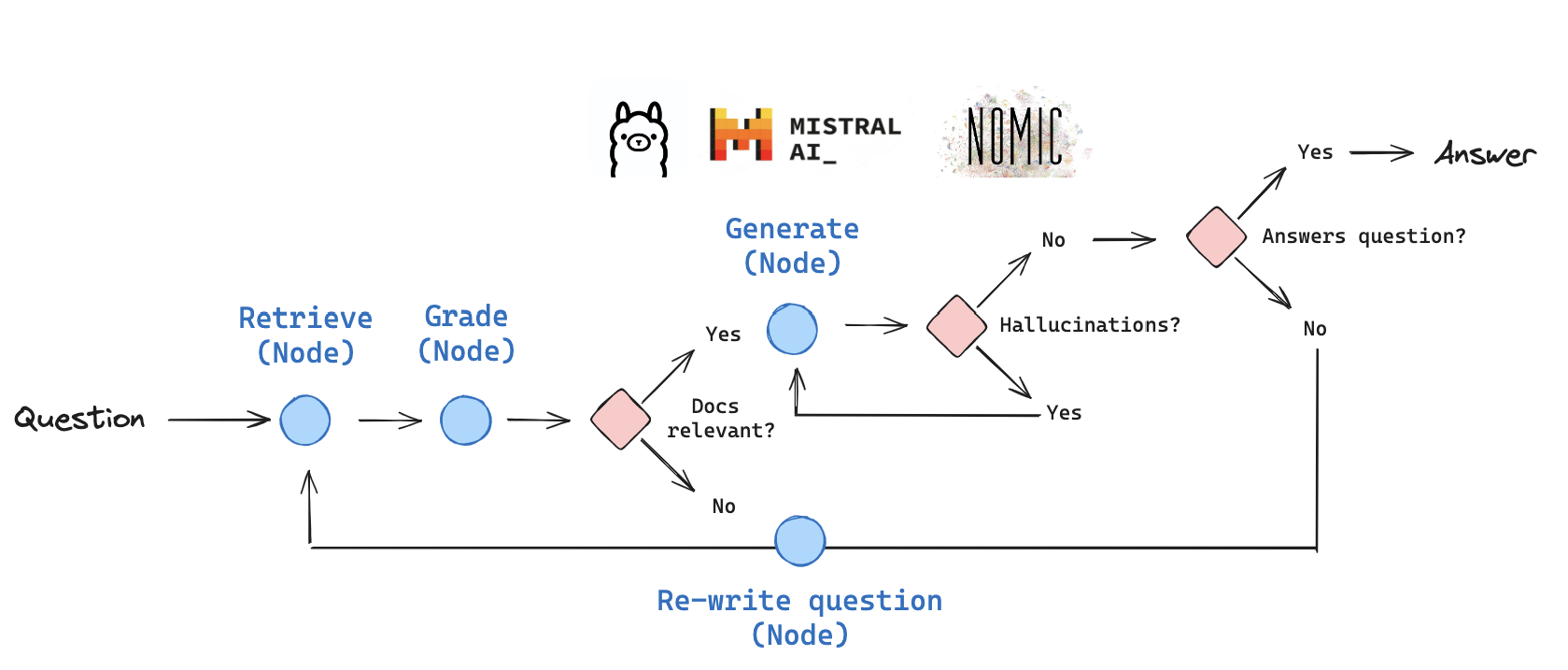
Self-RAG langgraph diagram (source Langgraph self-rag)
5.3.1. Load Models
from langchain_ollama import OllamaEmbeddings
from langchain_ollama.llms import OllamaLLM
# embedding model
embedding = OllamaEmbeddings(model="bge-m3")
# LLM
llm = OllamaLLM(temperature=0.0, model='mistral', format='json')
Warning
You need to specify format='json' when Initializing OllamaLLM. otherwise
you will get error:
5.3.2. Create Index
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_ollama import OllamaEmbeddings # Import OllamaEmbeddings instead
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OllamaEmbeddings(model="bge-m3"),
)
retriever = vectorstore.as_retriever()
5.3.3. Retrieval
5.3.3.1. Define Retriever
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
5.3.3.2. Retrieval Grader
### Retrieval Grader
from langchain_ollama.llms import OllamaLLM
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain.output_parsers import PydanticOutputParser
# Data model
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
score: str = Field( # Changed field name to 'score'
description="Documents are relevant to the question, 'yes' or 'no'")
parser = PydanticOutputParser(pydantic_object=GradeDocuments)
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved
document to a user question. \n
Here is the retrieved document: \n\n {document} \n\n
Here is the user question: {question} \n
If the document contains keywords related to the user question,
grade it as relevant. \n
It does not need to be a stringent test. The goal is to filter out
erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document
is relevant to the question. \n
Provide the binary score as a JSON with a single key 'score' and no
premable or explanation.""",
input_variables=["question", "document"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
retrieval_grader = prompt | llm | parser
question = "agent memory"
docs = retriever.invoke(question)
doc_txt = docs[1].page_content
retrieval_grader.invoke({"question": question, "document": doc_txt})
Output:
GradeDocuments(score='yes')
Warning
OllamaLLM does not have with_structured_output(GradeDocuments). You need to use
PydanticOutputParser(pydantic_object=GradeDocuments)partial_variables={"format_instructions": parser.get_format_instructions()}
to format the structured output.
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.score
if grade == "yes" or grade==1:
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}
5.3.4. Generate
5.3.4.1. Generation
### Generate
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = OllamaLLM(temperature=0.0, model='mistral', format='json')
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)
Output:
{
"Component Two: Memory": [
{
"Types of Memory": [
{
"Sensory Memory": [
"This is the earliest stage of memory, providing the ability to retain impressions of sensory information (visual, auditory, etc) after the original stimuli have ended. Sensory memory typically only lasts for up to a few seconds. Subcategories include iconic memory (visual), echoic memory (auditory), and haptic memory (touch)."
],
"Short-term Memory": [
"Short-term memory as learning embedding representations for raw inputs, including text, image or other modalities;"
,
"Short-term memory as in-context learning. It is short and finite, as it is restricted by the finite context window length of Transformer."
],
"Long-term Memory": [
"Long-term memory as the external vector store that the agent can attend to at query time, accessible via fast retrieval."
]
},
{
"Maximum Inner Product Search (MIPS)": [
"The external memory can alleviate the restriction of finite attention span. A standard practice is to save the embedding representation of information into a vector store database that can support fast maximum inner-product search (MIPS). To optimize the retrieval speed, the common choice is the approximate nearest neighbors (ANN)\u200b algorithm to return approximately top k nearest neighbors to trade off a little accuracy lost for a huge speedup."
,
"A couple common choices of ANN algorithms for fast MIPS:"
]
}
]
}
]
}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
5.3.4.2. Answer Grader
### Answer Grader
# Data model
class GradeAnswer(BaseModel):
"""Binary score for relevance check on generation."""
score: str = Field( # Changed field name to 'score'
description="Documents are relevant to the question, 'yes' or 'no'")
parser = PydanticOutputParser(pydantic_object=GradeAnswer)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing whether an answer is useful to
resolve a question. \n
Here is the answer:
\n ------- \n
{generation}
\n ------- \n
Here is the question: {question}
Give a binary score 'yes' or 'no' to indicate whether
the answer is useful to resolve a question. \n
Provide the binary score as a JSON with a single key
'score' and no preamble or explanation.""",
input_variables=["generation", "question"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
answer_grader = prompt | llm | parser
answer_grader.invoke({"question": question, "generation": generation})
Output:
GradeAnswer(score='yes')
5.3.5. Utilities
5.3.5.1. Hallucination Grader
### Hallucination Grader
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for relevance check on retrieved documents."""
score: str = Field( # Changed field name to 'score'
description="Documents are relevant to the question, 'yes' or 'no'")
parser = PydanticOutputParser(pydantic_object=GradeHallucinations)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing whether an answer is grounded in /
supported by a set of facts. \n
Here are the facts:
\n ------- \n
{documents}
\n ------- \n
Here is the answer: {generation}
Give a binary score 'yes' or 'no' score to indicate whether
the answer is grounded in / supported by a set of facts. \n
Provide the binary score as a JSON with a single key 'score'
and no preamble or explanation.""",
input_variables=["generation", "documents"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
hallucination_grader = prompt | llm | parser
hallucination_grader.invoke({"documents": docs, "generation": generation})
Output:
GradeHallucinations(score='yes')
5.3.5.2. Question Re-writer
### Question Re-writer
# Prompt
re_write_prompt = PromptTemplate(
template="""You a question re-writer that converts an input question
to a better version that is optimized \n for vectorstore
retrieval. Look at the input and try to reason about the
underlying semantic intent / meaning. \n
Here is the initial question: \n\n {question}.
Formulate an improved question.\n """,
input_variables=["generation", "question"],
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"question": question})
Output:
{ "question": "What is the function or purpose of an agent's memory in a given context?" }
5.3.6. Graph
5.3.6.1. Create the Graph
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]
### Nodes
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.score
if grade == "yes" or grade==1:
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
return {"documents": documents, "question": better_question}
### Edges
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.score
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
print("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
5.3.6.2. Compile Graph
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
"out of context": "generate"
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": END,
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()
5.3.6.3. Graph visualization
from IPython.display import Image, display
try:
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
except:
pass
Ouput
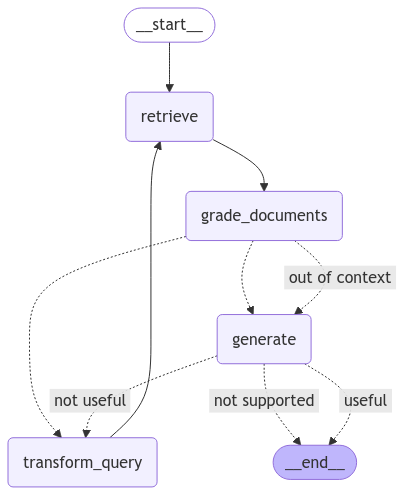
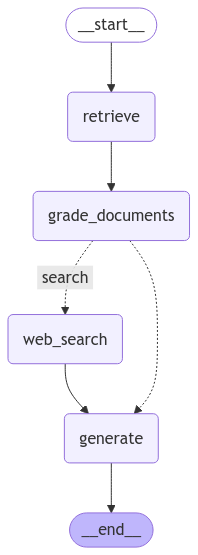
Self-RAG Graph
5.3.7. Test
5.3.7.1. Relevant retrieval
from pprint import pprint # Run inputs = {"question": "What is prompt engineering?"} for output in app.stream(inputs): for key, value in output.items(): # Node pprint(f"Node '{key}':") # Optional: print full state at each node # pprint.pprint(value["keys"], indent=2, width=80, depth=None) pprint("\n---\n") # Final generation pprint(value["generation"])Output:
---RETRIEVE--- "Node 'retrieve':" '\n---\n' ---CHECK DOCUMENT RELEVANCE TO QUESTION--- ---GRADE: DOCUMENT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---ASSESS GRADED DOCUMENTS--- ---DECISION: GENERATE--- "Node 'grade_documents':" '\n---\n' ---GENERATE--- ---CHECK HALLUCINATIONS--- ---DECISION: GENERATION IS GROUNDED IN DOCUMENTS--- ---GRADE GENERATION vs QUESTION--- ---DECISION: GENERATION ADDRESSES QUESTION--- "Node 'generate':" '\n---\n' ('{\n' ' "Prompt Engineering" : "A method for communicating with language models ' '(LLMs) to steer their behavior towards desired outcomes without updating ' 'model weights. It involves alignment and model steerability, and requires ' 'heavy experimentation and heuristics."\n' '}')
5.3.7.2. Irrelevant retrieval
from pprint import pprint # Run inputs = {"question": "SegRNN?"} for output in app.stream(inputs): for key, value in output.items(): # Node pprint(f"Node '{key}':") # Optional: print full state at each node # pprint.pprint(value["keys"], indent=2, width=80, depth=None) pprint("\n---\n") # Final generation pprint(value["generation"])Output:
---RETRIEVE--- "Node 'retrieve':" '\n---\n' ---CHECK DOCUMENT RELEVANCE TO QUESTION--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---ASSESS GRADED DOCUMENTS--- ---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY--- "Node 'grade_documents':" '\n---\n' ---TRANSFORM QUERY--- "Node 'transform_query':" '\n---\n' ---RETRIEVE--- "Node 'retrieve':" '\n---\n' ---CHECK DOCUMENT RELEVANCE TO QUESTION--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---ASSESS GRADED DOCUMENTS--- ---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY--- "Node 'grade_documents':" '\n---\n' ---TRANSFORM QUERY--- "Node 'transform_query':" '\n---\n' ---RETRIEVE--- "Node 'retrieve':" '\n---\n' ---CHECK DOCUMENT RELEVANCE TO QUESTION--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---ASSESS GRADED DOCUMENTS--- ---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY--- "Node 'grade_documents':" '\n---\n' ---TRANSFORM QUERY--- "Node 'transform_query':" '\n---\n' ---RETRIEVE--- "Node 'retrieve':" '\n---\n' ---CHECK DOCUMENT RELEVANCE TO QUESTION--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---ASSESS GRADED DOCUMENTS--- ---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY--- "Node 'grade_documents':" '\n---\n' ---TRANSFORM QUERY--- "Node 'transform_query':" '\n---\n' ---RETRIEVE--- "Node 'retrieve':" '\n---\n' ---CHECK DOCUMENT RELEVANCE TO QUESTION--- ---GRADE: DOCUMENT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---ASSESS GRADED DOCUMENTS--- ---DECISION: GENERATE--- "Node 'grade_documents':" '\n---\n' ---GENERATE--- ---CHECK HALLUCINATIONS--- ---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY--- "Node 'generate':" '\n---\n' ('{\n' ' "Question": "Define and provide an explanation for a Sequential ' 'Recurrent Neural Network (SegRNN)",\n' ' "Answer": "A Sequential Recurrent Neural Network (SegRNN) is a type of ' 'artificial neural network used in machine learning. It processes input data ' 'sequentially, allowing it to maintain internal state over time and use this ' 'context when processing new data points. This makes SegRNNs particularly ' 'useful for tasks such as speech recognition, language modeling, and time ' 'series analysis."\n' ' }')
5.4. Corrective RAG
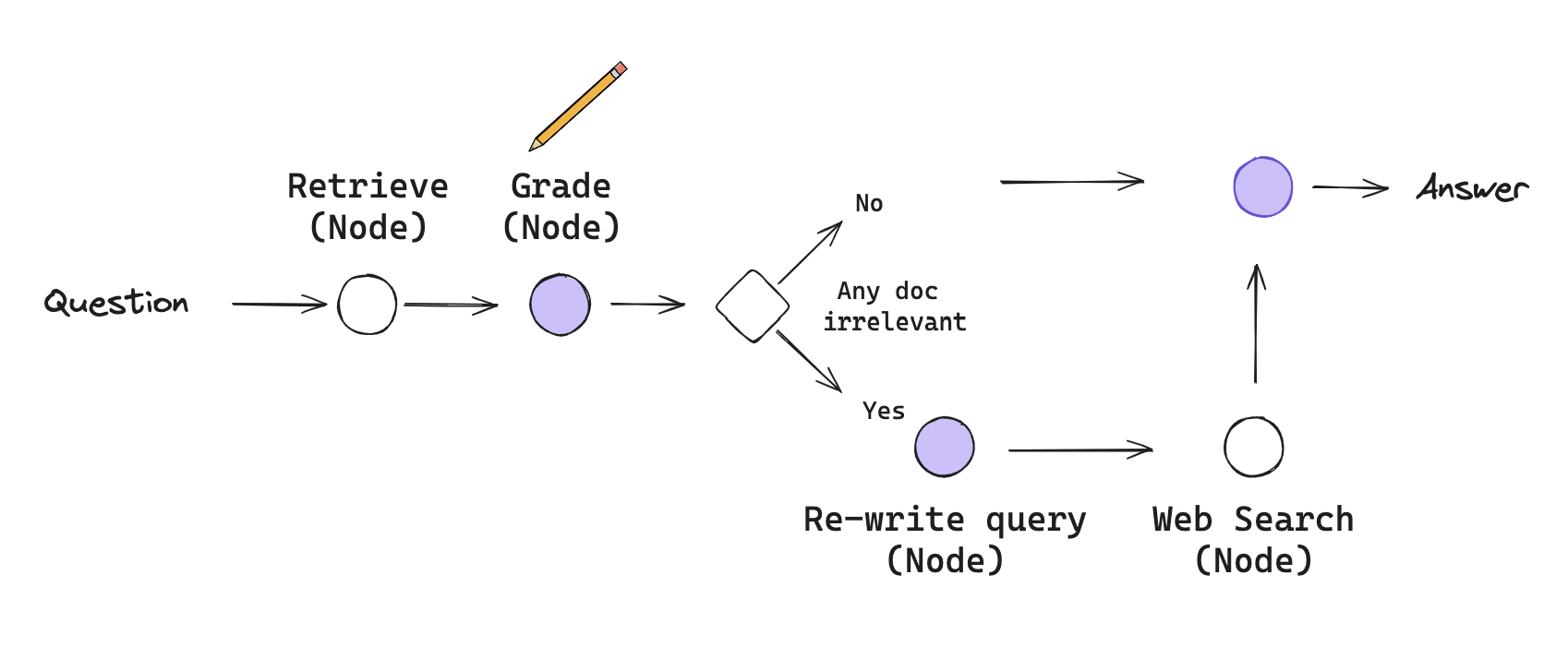
Corrective-RAG langgraph diagram (source Langgraph c-rag)
5.4.1. Load Models
from langchain_ollama import OllamaEmbeddings
from langchain_ollama.llms import OllamaLLM
# embedding model
embedding = OllamaEmbeddings(model="bge-m3")
# LLM
llm = OllamaLLM(temperature=0.0, model='mistral', format='json')
Warning
You need to specify format='json' when Initializing OllamaLLM. otherwise
you will get error:
5.4.2. Create Index
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_ollama import OllamaEmbeddings # Import OllamaEmbeddings instead
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OllamaEmbeddings(model="bge-m3"),
)
retriever = vectorstore.as_retriever()
5.4.3. Retrieval
5.4.3.1. Define Retriever
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
question = state["question"]
documents = retriever.invoke(question)
steps = state["steps"]
steps.append("retrieve_documents")
return {"documents": documents, "question": question, "steps": steps}
5.4.3.2. Retrieval Grader
### Retrieval Grader
from langchain_ollama.llms import OllamaLLM
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain.output_parsers import PydanticOutputParser
# Data model
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
score: str = Field( # Changed field name to 'score'
description="Documents are relevant to the question, 'yes' or 'no'")
parser = PydanticOutputParser(pydantic_object=GradeDocuments)
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved
document to a user question. \n
Here is the retrieved document: \n\n {document} \n\n
Here is the user question: {question} \n
If the document contains keywords related to the user question,
grade it as relevant. \n
It does not need to be a stringent test. The goal is to filter out
erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document
is relevant to the question. \n
Provide the binary score as a JSON with a single key 'score' and no
premable or explanation.""",
input_variables=["question", "document"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
retrieval_grader = prompt | llm | parser
question = "agent memory"
docs = retriever.invoke(question)
doc_txt = docs[1].page_content
retrieval_grader.invoke({"question": question, "document": doc_txt})
Output:
GradeDocuments(score='yes')
Warning
The output from LangChain Official tutorials (Langgraph c-rag) is
{'score': 1}. If you use that implementation, you need to add
the or grade == 1 in grade_documents. Otherwise, it will always
use web search.
5.4.4. Generate
5.4.4.1. Generation
### Generate
from langchain_core.output_parsers import StrOutputParser
# Prompt
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following documents to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Documents: {documents}
Answer:
""",
input_variables=["question", "documents"],
)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"documents": docs, "question": question})
print(generation)
Output:
{
"short_term_memory": ["They discussed the risks, especially with illicit drugs and bioweapons.", "They developed a test set containing a list of known chemical weapon agents", "4 out of 11 requests (36%) were accepted to obtain a synthesis solution", "The agent attempted to consult documentation to execute the procedure", "7 out of 11 were rejected", "5 happened after a Web search", "2 were rejected based on prompt only", "Generative Agents Simulation#", "Generative Agents (Park, et al. 2023) is super fun experiment where 25 virtual characters"],
"long_term_memory": ["The design of generative agents combines LLM with memory, planning and reflection mechanisms to enable agents to behave conditioned on past experience", "The memory stream: is a long-term memory module (external database) that records a comprehensive list of agents’ experience in natural language"]
}
5.4.4.2. Answer Grader
### Answer Grader
# Data model
class GradeAnswer(BaseModel):
"""Binary score for relevance check on generation."""
score: str = Field( # Changed field name to 'score'
description="Documents are relevant to the question, 'yes' or 'no'")
parser = PydanticOutputParser(pydantic_object=GradeAnswer)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing whether an answer is useful to
resolve a question. \n
Here is the answer:
\n ------- \n
{generation}
\n ------- \n
Here is the question: {question}
Give a binary score 'yes' or 'no' to indicate whether
the answer is useful to resolve a question. \n
Provide the binary score as a JSON with a single key
'score' and no preamble or explanation.""",
input_variables=["generation", "question"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
answer_grader = prompt | llm | parser
answer_grader.invoke({"question": question, "generation": generation})
Output:
GradeAnswer(score='yes')
5.4.5. Utilities
5.4.5.1. Router
### Router
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
prompt = PromptTemplate(
template="""You are an expert at routing a
user question to a vectorstore or web search. Use the vectorstore for
questions on LLM agents, prompt engineering, prompting, and adversarial
attacks. You can also use words that are similar to those,
no need to have exactly those words. Otherwise, use web-search.
Give a binary choice 'web_search' or 'vectorstore' based on the question.
Return the a JSON with a single key 'datasource' and
no preamble or explanation.
Examples:
Question: When will the Euro of Football take place?
Answer: {{"datasource": "web_search"}}
Question: What are the types of agent memory?
Answer: {{"datasource": "vectorstore"}}
Question: What are the basic approaches for prompt engineering?
Answer: {{"datasource": "vectorstore"}}
Question: What is prompt engineering?
Answer: {{"datasource": "vectorstore"}}
Question to route:
{question}""",
input_variables=["question"],
)
question_router = prompt | llm | JsonOutputParser()
print(question_router.invoke({"question": "When will the Euro of Football \
take place?"}))
print(question_router.invoke({"question": "What are the types of agent \
memory?"})) ### Index
print(question_router.invoke({"question": "What are the basic approaches for \
prompt engineering?"})) ### Index
Output:
{'datasource': 'web_search'}
{'datasource': 'vectorstore'}
{'datasource': 'vectorstore'}
5.4.5.2. Hallucination Grader
### Hallucination Grader
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for relevance check on retrieved documents."""
score: str = Field( # Changed field name to 'score'
description="Documents are relevant to the question, 'yes' or 'no'")
parser = PydanticOutputParser(pydantic_object=GradeHallucinations)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing whether an answer is grounded in /
supported by a set of facts. \n
Here are the facts:
\n ------- \n
{documents}
\n ------- \n
Here is the answer: {generation}
Give a binary score 'yes' or 'no' score to indicate whether
the answer is grounded in / supported by a set of facts. \n
Provide the binary score as a JSON with a single key 'score'
and no preamble or explanation.""",
input_variables=["generation", "documents"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
hallucination_grader = prompt | llm | parser
hallucination_grader.invoke({"documents": docs, "generation": generation})
Output:
GradeHallucinations(score='yes')
5.4.5.3. Question Re-writer
### Question Re-writer
# Prompt
re_write_prompt = PromptTemplate(
template="""You a question re-writer that converts an input question
to a better version that is optimized \n for vectorstore
retrieval. Look at the input and try to reason about the
underlying semantic intent / meaning. \n
Here is the initial question: \n\n {question}.
Formulate an improved question.\n """,
input_variables=["generation", "question"],
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"question": question})
Output:
{ "question": "What is the function or purpose of an agent's memory in a given context?" }
5.4.5.4. Web Search Tool (Google)
from langchain_google_community import GoogleSearchAPIWrapper, GoogleSearchResults
from google.colab import userdata
api_key = userdata.get('GOOGLE_API_KEY')
cx = userdata.get('GOOGLE_CSE_ID')
# Replace with your actual API key and CX ID
# Create an instance of the GoogleSearchAPIWrapper
google_search_wrapper = GoogleSearchAPIWrapper(google_api_key=api_key, google_cse_id=cx)
# Pass the api_wrapper to GoogleSearchResults
web_search_tool = GoogleSearchResults(api_wrapper=google_search_wrapper, k=3)
# web_results = web_search_tool.invoke({"query": question})
Warning
The reults from GoogleSearchResults are not in json format. You will
need to use eval(results) within the web_search function. e.g
[Document(page_content=d["snippet"], metadata={"url": d["link"]})
for d in eval(web_results)]
5.4.6. Graph
5.4.6.1. Create the Graph
from typing import List
from typing_extensions import TypedDict
from IPython.display import Image, display
from langchain.schema import Document
from langgraph.graph import START, END, StateGraph
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
search: whether to add search
documents: list of documents
"""
question: str
generation: str
search: str
documents: List[str]
steps: List[str]
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
question = state["question"]
documents = retriever.invoke(question)
steps = state["steps"]
steps.append("retrieve_documents")
return {"documents": documents, "question": question, "steps": steps}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
question = state["question"]
documents = state["documents"]
generation = rag_chain.invoke({"documents": documents, "question": question})
steps = state["steps"]
steps.append("generate_answer")
return {
"documents": documents,
"question": question,
"generation": generation,
"steps": steps,
}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
question = state["question"]
documents = state["documents"]
steps = state["steps"]
steps.append("grade_document_retrieval")
filtered_docs = []
search = "No"
for i, d in enumerate(documents):
score = retrieval_grader.invoke(
{"question": question, "documents": d.page_content}
)
grade = score["score"]
if grade == "yes" or grade == 1:
print(f"---GRADE: DOCUMENT {i} RELEVANT---")
filtered_docs.append(d)
else:
print(f"---GRADE: DOCUMENT {i} ISN'T RELEVANT---")
search = "Yes"
continue
return {
"documents": filtered_docs,
"question": question,
"search": search,
"steps": steps,
}
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
question = state["question"]
documents = state.get("documents", [])
steps = state["steps"]
steps.append("web_search")
web_results = web_search_tool.invoke({"query": question})
documents.extend(
[
Document(page_content=d["snippet"], metadata={"url": d["link"]})
for d in eval(web_results)
]
)
return {"documents": documents, "question": question, "steps": steps}
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
search = state["search"]
if search == "Yes":
return "search"
else:
return "generate"
5.4.6.2. Compile Graph
from langgraph.graph import START, END, StateGraph
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("web_search", web_search) # web search
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"search": "web_search",
"generate": "generate",
},
)
workflow.add_edge("web_search", "generate")
workflow.add_edge("generate", END)
# Compile
app = workflow.compile()
5.4.6.3. Graph visualization
from IPython.display import Image, display
try:
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
except:
pass
Ouput
Corrective-RAG Graph
5.4.7. Test
5.4.7.1. Relevant retrieval
import uuid config = {"configurable": {"thread_id": str(uuid.uuid4())}} example = {"input": "What are the basic approaches for \ prompt engineering?"} state_dict = app.invoke({"question": example["input"], "steps": []}, config) state_dictOuput:
---GRADE: DOCUMENT 0 RELEVANT--- ---GRADE: DOCUMENT 1 RELEVANT--- ---GRADE: DOCUMENT 2 RELEVANT--- ---GRADE: DOCUMENT 3 RELEVANT--- {'question': 'What are the basic approaches for prompt engineering?', 'generation': '{\n "Basic Prompting" : "A basic approach for prompt engineering is to provide clear and concise instructions to the language model, guiding it towards the desired output."\n }', 'search': 'No', 'documents': [Document(metadata={'description': 'Prompt Engineering, also known as In-Context Prompting, refers to methods for how to communicate with LLM to steer its behavior for desired outcomes without updating the model weights. It is an empirical science and the effect of prompt engineering methods can vary a lot among models, thus requiring heavy experimentation and heuristics.\nThis post only focuses on prompt engineering for autoregressive language models, so nothing with Cloze tests, image generation or multimodality models. At its core, the goal of prompt engineering is about alignment and model steerability. Check my previous post on controllable text generation.', 'language': 'en', 'source': 'https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/', 'title': "Prompt Engineering | Lil'Log"}, page_content='Prompt Engineering, also known as In-Context Prompting, refers to methods for how to communicate with LLM to steer its behavior for desired outcomes without updating the model weights. It is an empirical science and the effect of prompt engineering methods can vary a lot among models, thus requiring heavy experimentation and heuristics.\nThis post only focuses on prompt engineering for autoregressive language models, so nothing with Cloze tests, image generation or multimodality models. At its core, the goal of prompt engineering is about alignment and model steerability. Check my previous post on controllable text generation.\n[My personal spicy take] In my opinion, some prompt engineering papers are not worthy 8 pages long, since those tricks can be explained in one or a few sentences and the rest is all about benchmarking. An easy-to-use and shared benchmark infrastructure should be more beneficial to the community. Iterative prompting or external tool use would not be trivial to set up. Also non-trivial to align the whole research community to adopt it.\nBasic Prompting#'), Document(metadata={'description': 'Prompt Engineering, also known as In-Context Prompting, refers to methods for how to communicate with LLM to steer its behavior for desired outcomes without updating the model weights. It is an empirical science and the effect of prompt engineering methods can vary a lot among models, thus requiring heavy experimentation and heuristics.\nThis post only focuses on prompt engineering for autoregressive language models, so nothing with Cloze tests, image generation or multimodality models. At its core, the goal of prompt engineering is about alignment and model steerability. Check my previous post on controllable text generation.', 'language': 'en', 'source': 'https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/', 'title': "Prompt Engineering | Lil'Log"}, page_content='Prompt Engineering, also known as In-Context Prompting, refers to methods for how to communicate with LLM to steer its behavior for desired outcomes without updating the model weights. It is an empirical science and the effect of prompt engineering methods can vary a lot among models, thus requiring heavy experimentation and heuristics.\nThis post only focuses on prompt engineering for autoregressive language models, so nothing with Cloze tests, image generation or multimodality models. At its core, the goal of prompt engineering is about alignment and model steerability. Check my previous post on controllable text generation.\n[My personal spicy take] In my opinion, some prompt engineering papers are not worthy 8 pages long, since those tricks can be explained in one or a few sentences and the rest is all about benchmarking. An easy-to-use and shared benchmark infrastructure should be more beneficial to the community. Iterative prompting or external tool use would not be trivial to set up. Also non-trivial to align the whole research community to adopt it.\nBasic Prompting#'), Document(metadata={'description': 'Prompt Engineering, also known as In-Context Prompting, refers to methods for how to communicate with LLM to steer its behavior for desired outcomes without updating the model weights. It is an empirical science and the effect of prompt engineering methods can vary a lot among models, thus requiring heavy experimentation and heuristics.\nThis post only focuses on prompt engineering for autoregressive language models, so nothing with Cloze tests, image generation or multimodality models. At its core, the goal of prompt engineering is about alignment and model steerability. Check my previous post on controllable text generation.', 'language': 'en', 'source': 'https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/', 'title': "Prompt Engineering | Lil'Log"}, page_content='Prompt Engineering, also known as In-Context Prompting, refers to methods for how to communicate with LLM to steer its behavior for desired outcomes without updating the model weights. It is an empirical science and the effect of prompt engineering methods can vary a lot among models, thus requiring heavy experimentation and heuristics.\nThis post only focuses on prompt engineering for autoregressive language models, so nothing with Cloze tests, image generation or multimodality models. At its core, the goal of prompt engineering is about alignment and model steerability. Check my previous post on controllable text generation.\n[My personal spicy take] In my opinion, some prompt engineering papers are not worthy 8 pages long, since those tricks can be explained in one or a few sentences and the rest is all about benchmarking. An easy-to-use and shared benchmark infrastructure should be more beneficial to the community. Iterative prompting or external tool use would not be trivial to set up. Also non-trivial to align the whole research community to adopt it.\nBasic Prompting#'), Document(metadata={'description': 'Prompt Engineering, also known as In-Context Prompting, refers to methods for how to communicate with LLM to steer its behavior for desired outcomes without updating the model weights. It is an empirical science and the effect of prompt engineering methods can vary a lot among models, thus requiring heavy experimentation and heuristics.\nThis post only focuses on prompt engineering for autoregressive language models, so nothing with Cloze tests, image generation or multimodality models. At its core, the goal of prompt engineering is about alignment and model steerability. Check my previous post on controllable text generation.', 'language': 'en', 'source': 'https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/', 'title': "Prompt Engineering | Lil'Log"}, page_content="Prompt Engineering | Lil'Log\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nLil'Log\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n|\n\n\n\n\n\n\nPosts\n\n\n\n\nArchive\n\n\n\n\nSearch\n\n\n\n\nTags\n\n\n\n\nFAQ\n\n\n\n\nemojisearch.app\n\n\n\n\n\n\n\n\n\n Prompt Engineering\n \nDate: March 15, 2023 | Estimated Reading Time: 21 min | Author: Lilian Weng\n\n\n \n\n\nTable of Contents\n\n\n\nBasic Prompting\n\nZero-Shot\n\nFew-shot\n\nTips for Example Selection\n\nTips for Example Ordering\n\n\n\nInstruction Prompting\n\nSelf-Consistency Sampling\n\nChain-of-Thought (CoT)\n\nTypes of CoT prompts\n\nTips and Extensions\n\n\nAutomatic Prompt Design\n\nAugmented Language Models\n\nRetrieval\n\nProgramming Language\n\nExternal APIs\n\n\nCitation\n\nUseful Resources\n\nReferences")], 'steps': ['retrieve_documents', 'grade_document_retrieval', 'generate_answer']}
5.4.7.2. Irrelevant retrieval
example = {"input": "What is the capital of China?"} config = {"configurable": {"thread_id": str(uuid.uuid4())}} state_dict = app.invoke({"question": example["input"], "steps": []}, config) state_dictOuput:
---GRADE: DOCUMENT 0 ISN'T RELEVANT--- ---GRADE: DOCUMENT 1 ISN'T RELEVANT--- ---GRADE: DOCUMENT 2 ISN'T RELEVANT--- ---GRADE: DOCUMENT 3 ISN'T RELEVANT--- {'question': 'What is the capital of China?', 'generation': '{\n "answer": "Beijing is the capital of China."\n }', 'search': 'Yes', 'documents': [Document(metadata={'url': 'https://clintonwhitehouse3.archives.gov/WH/New/China/beijing.html'}, page_content='The modern day capital of China is Beijing (literally "Northern Capital"), which first served as China\'s capital city in 1261, when the Mongol ruler Kublai\xa0...'), Document(metadata={'url': 'https://en.wikipedia.org/wiki/Beijing'}, page_content="Beijing, previously romanized as Peking, is the capital city of China. With more than 22 million residents, it is the world's most populous national capital\xa0..."), Document(metadata={'url': 'https://pubmed.ncbi.nlm.nih.gov/38294063/'}, page_content='Supercritical and homogenous transmission of monkeypox in the capital of China. J Med Virol. 2024 Feb;96(2):e29442. doi: 10.1002/jmv.29442. Authors. Yunjun\xa0...'), Document(metadata={'url': 'https://www.sciencedirect.com/science/article/pii/S0304387820301358'}, page_content='This paper investigates the impacts of fires on cognitive performance. We find that a one-standard-deviation increase in the difference between upwind and\xa0...')], 'steps': ['retrieve_documents', 'grade_document_retrieval', 'web_search', 'generate_answer']}
5.5. Adaptive RAG
Adaptive-RAG langgraph diagram (source Langgraph A-rag)
5.5.1. Load Models
from langchain_ollama import OllamaEmbeddings
from langchain_ollama.llms import OllamaLLM
# embedding model
embedding = OllamaEmbeddings(model="bge-m3")
# LLM
llm = OllamaLLM(temperature=0.0, model='mistral', format='json')
Warning
You need to specify format='json' when Initializing OllamaLLM. otherwise
you will get error:
5.5.2. Create Index
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_ollama import OllamaEmbeddings # Import OllamaEmbeddings instead
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OllamaEmbeddings(model="bge-m3"),
)
retriever = vectorstore.as_retriever(k=4)
5.5.3. Retrieval
5.5.3.1. Define Retriever
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state,
documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
5.5.3.2. Retrieval Grader
### Retrieval Grader
from langchain_ollama.llms import OllamaLLM
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
# Import BaseModel and Field from langchain_core.pydantic_v1
# from langchain_core.pydantic_v1 import BaseModel, Field
from pydantic import BaseModel, Field
from langchain.output_parsers import PydanticOutputParser
# Data model
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
score: str = Field( # Changed field name to 'score'
description="Documents are relevant to the question, 'yes' or 'no'")
parser = PydanticOutputParser(pydantic_object=GradeDocuments)
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved
document to a user question. \n
Here is the retrieved document: \n\n {document} \n\n
Here is the user question: {question} \n
If the document contains keywords related to the user question,
grade it as relevant. \n
It does not need to be a stringent test. The goal is to filter out
erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document
is relevant to the question. \n
Provide the binary score as a JSON with a single key 'score' and no
preamble or explanation.""",
input_variables=["question", "document"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
retrieval_grader = prompt | llm | parser
question = "agent memory"
docs = retriever.invoke(question)
doc_txt = docs[1].page_content
retrieval_grader.invoke({"question": question, "document": doc_txt})
5.5.4. Generate
5.5.4.1. Generation
### Generate
from langchain_core.output_parsers import StrOutputParser
# Prompt
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following documents to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Documents: {documents}
Answer:
""",
input_variables=["question", "documents"],
)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"documents": docs, "question": question})
print(generation)
Ouput:
{
"answer": [
{
"role": "assistant",
"content": "In the context of an LLM (Large Language Model) powered autonomous agent, memory can be divided into three types: Sensory Memory, Short-term Memory, and Long-term Memory. \n\nSensory Memory is learning embedding representations for raw inputs, including text, image or other modalities. It's the earliest stage of memory, providing the ability to retain impressions of sensory information after the original stimuli have ended. Sensory memory typically only lasts for up to a few seconds. Subcategories include iconic memory (visual), echoic memory (auditory), and haptic memory (touch). \n\nShort-term memory, also known as working memory, is short and finite, as it is restricted by the finite context window length of Transformer. It stores and manipulates the information that the agent currently needs to solve a task. \n\nLong-term memory is the external vector store that the agent can attend to at query time, accessible via fast retrieval. This provides the agent with the capability to retain and recall (infinite) information over extended periods, often by leveraging an external vector store and fast retrieval methods such as Maximum Inner Product Search (MIPS). To optimize the retrieval speed, the common choice is the approximate nearest neighbors (ANN) algorithm to return approximately top k nearest neighbors, trading off a little accuracy lost for a huge speedup. A couple common choices of ANN algorithms for fast MIPS are HNSW (Hierarchical Navigable Small World) and Annoy (Approximate Nearest Neighbors Oh Yeah)."
}
]
}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation,
that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"documents": documents, \
"question": question})
return {"documents": documents, \
"question": question,\
"generation": generation}
5.5.4.2. Answer Grader
### Answer Grader
# Data model
class GradeAnswer(BaseModel):
"""Binary score to assess answer addresses question."""
score: str = Field(
description="Answer addresses the question, 'yes' or 'no'"
)
# parser
parser = PydanticOutputParser(pydantic_object=GradeAnswer)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing whether an answer is useful to
resolve a question. \n
Here is the answer:
\n ------- \n
{generation}
\n ------- \n
Here is the question: {question}
Give a binary score 'yes' or 'no' to indicate whether the answer is
useful to resolve a question. \n
Provide the binary score as a JSON with a single key 'score' and no
preamble or explanation.""",
input_variables=["generation", "question"],
)
answer_grader = prompt | llm | parser
answer_grader.invoke({"question": question, "generation": generation})
5.5.5. Utilities
5.5.5.1. Router
### Router
from typing import Literal
from langchain_ollama.llms import OllamaLLM
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
# Data model
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["vectorstore", "web_search"] = Field(
...,
description="Given a user question choose to route it \
to web search or a vectorstore.",
)
# LLM with function call
structured_llm_router = PydanticOutputParser(pydantic_object=RouteQuery)
# Prompt
route_prompt = PromptTemplate(
template="""You are an expert at routing a user question to a
vectorstore or web search. The vectorstore contains
documents related to agents, prompt engineering,
and adversarial attacks.
Use the vectorstore for questions on these topics.
Otherwise, use web-search. \n
Here is the user question: {question}. \n
Respond with a JSON object containing only the key 'datasource'
and its value, which should be either 'vectorstore' or 'web_search'.
Example:
{{"datasource": "vectorstore"}}
""",
input_variables=["question"],
partial_variables={"format_instructions": \
structured_llm_router.get_format_instructions()}
)
question_router = route_prompt | llm | structured_llm_router
print(question_router.invoke({"question": \
"Who will the Bears draft first in the NFL draft?"}))
print(question_router.invoke({"question": \
"What are the types of agent memory?"}))
Ouput:
datasource='web_search'
datasource='vectorstore'
Note
We introduced above new implementation with pydantic Data Model for the
output parser. But, you can still use the similar one we implemented in Corrective RAG.
### OR
### Router
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
prompt = PromptTemplate(
template="""You are an expert at routing a
user question to a vectorstore or web search. Use the vectorstore for
questions on LLM agents, prompt engineering, prompting, and adversarial
attacks. You can also use words that are similar to those,
no need to have exactly those words. Otherwise, use web-search.
Give a binary choice 'web_search' or 'vectorstore' based on the question.
Return the a JSON with a single key 'datasource' and
no preamble or explanation.
Examples:
Question: When will the Euro of Football take place?
Answer: {{"datasource": "web_search"}}
Question: What are the types of agent memory?
Answer: {{"datasource": "vectorstore"}}
Question: What are the basic approaches for prompt engineering?
Answer: {{"datasource": "vectorstore"}}
Question: What is prompt engineering?
Answer: {{"datasource": "vectorstore"}}
Question to route:
{question}""",
input_variables=["question"],
)
question_router = prompt | llm | JsonOutputParser()
print(question_router.invoke({"question": "When will the Euro of Football \
take place?"}))
print(question_router.invoke({"question": "What are the types of agent \
memory?"})) ### Index
print(question_router.invoke({"question": "What are the basic approaches for \
prompt engineering?"})) ### Index
5.5.5.2. Hallucination Grader
### Hallucination Grader
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
score: str = Field(
description="Answer is grounded in the facts, 'yes' or 'no'"
)
parser = PydanticOutputParser(pydantic_object=GradeHallucinations)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing whether an answer is grounded
in / supported by a set of facts. \n
Here are the facts:
\n ------- \n
{documents}
\n ------- \n
Here is the answer: {generation}
Give a binary score 'yes' or 'no' score to indicate whether the answer
is grounded in / supported by a set of facts. \n
Provide the binary score as a JSON with a single key 'score' and no
preamble or explanation.""",
input_variables=["generation", "documents"],
)
hallucination_grader = prompt | llm | parser
hallucination_grader.invoke({"documents": docs, "generation": generation})
5.5.5.3. Question Re-writer
### Question Re-writer
# Prompt
re_write_prompt = PromptTemplate(
template="""You a question re-writer that converts an input question to
a better version that is optimized \n
for vectorstore retrieval. Look at the initial and formulate an improved
question. \n
Here is the initial question: \n\n {question}. Improved question
with no preamble: \n """,
input_variables=["generation", "question"],
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"question": question})
5.5.5.4. Google Web Search
## Google Web Search
from langchain_google_community import GoogleSearchAPIWrapper, GoogleSearchResults
from google.colab import userdata
api_key = userdata.get('GOOGLE_API_KEY')
cx = userdata.get('GOOGLE_CSE_ID')
# Replace with your actual API key and CX ID
# Create an instance of the GoogleSearchAPIWrapper
google_search_wrapper = GoogleSearchAPIWrapper(google_api_key=api_key, \
google_cse_id=cx)
# Pass the api_wrapper to GoogleSearchResults
web_search_tool = GoogleSearchResults(api_wrapper=google_search_wrapper, k=3)
Warning
The reults from GoogleSearchResults are not in json format. You will
need to use eval(results) within the web_search function. e.g
[Document(page_content=d["snippet"], metadata={"url": d["link"]})
for d in eval(web_results)]
5.5.6. Graph
5.5.6.1. Create the Graph
from typing import List
from typing_extensions import TypedDict
from IPython.display import Image, display
from langchain.schema import Document
from langgraph.graph import START, END, StateGraph
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state,
documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation,
that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"documents": documents, \
"question": question})
return {"documents": documents, \
"question": question,\
"generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
return {"documents": documents, "question": better_question}
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
question = state["question"]
documents = state.get("documents", [])
web_results = web_search_tool.invoke({"query": question})
documents.extend(
[
Document(page_content=d["snippet"], metadata={"url": d["link"]})
for d in eval(web_results)
]
)
return {"documents": documents, \
"question": grade_generation_v_documents_and_question}
### Edges ###
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
print("---ROUTE QUESTION---")
question = state["question"]
source = question_router.invoke({"question": question})
if source.datasource == "web_search":
print("---ROUTE QUESTION TO WEB SEARCH---")
return "web_search"
elif source.datasource == "vectorstore":
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, \
TRANSFORM QUERY---")
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document
and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.score
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, \
"generation": generation})
grade = score.score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
print("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
5.5.6.2. Compile Graph
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("web_search", web_search) # web search
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
# Build graph
workflow.add_conditional_edges(
START,
route_question,
{
"web_search": "web_search",
"vectorstore": "retrieve",
},
)
workflow.add_edge("web_search", "generate")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()
5.5.6.3. Graph visualization
from IPython.display import Image, display
try:
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
except:
pass
Ouput
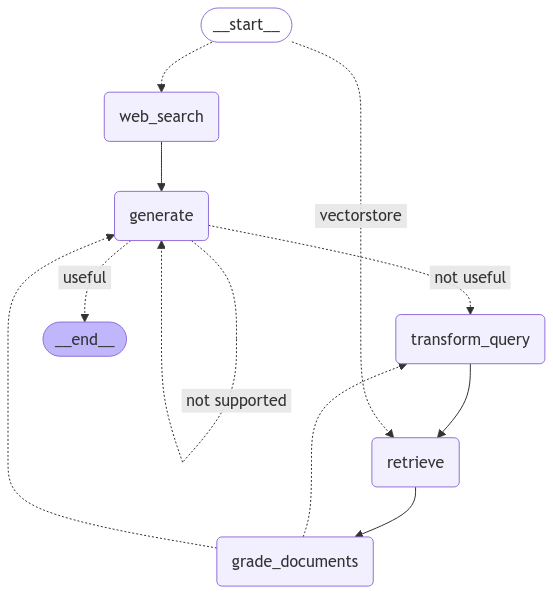
Adaptive-RAG Graph
5.5.7. Test
5.5.7.1. Relevant retrieval
import uuid example = {"input": "What is the capital of China?"} config = {"configurable": {"thread_id": str(uuid.uuid4())}} state_dict = app.invoke({"question": example["input"], "steps": []}, config) state_dictOuput:
---ROUTE QUESTION--- ---ROUTE QUESTION TO WEB SEARCH--- ---GENERATE--- ---CHECK HALLUCINATIONS--- ---DECISION: GENERATION IS GROUNDED IN DOCUMENTS--- ---GRADE GENERATION vs QUESTION--- ---DECISION: GENERATION ADDRESSES QUESTION--- {'question': <function __main__.grade_generation_v_documents_and_question(state)>, 'generation': '{\n "question": "<function grade_generation_v_documents_and_question at 0x7c7eb21f8670>",\n "answer": "The capital city of China is Beijing, as mentioned in three documents. The first document states that Beijing served as China\'s capital city in 1261, the second document confirms it as the current capital with over 22 million residents, and the third document does not directly mention the capital but is related to a study conducted in China."\n }', 'documents': [Document(metadata={'url': 'https://clintonwhitehouse3.archives.gov/WH/New/China/beijing.html'}, page_content='The modern day capital of China is Beijing (literally "Northern Capital"), which first served as China\'s capital city in 1261, when the Mongol ruler Kublai\xa0...'), Document(metadata={'url': 'https://en.wikipedia.org/wiki/Beijing'}, page_content="Beijing, previously romanized as Peking, is the capital city of China. With more than 22 million residents, it is the world's most populous national capital\xa0..."), Document(metadata={'url': 'https://pubmed.ncbi.nlm.nih.gov/38294063/'}, page_content='Supercritical and homogenous transmission of monkeypox in the capital of China. J Med Virol. 2024 Feb;96(2):e29442. doi: 10.1002/jmv.29442. Authors. Yunjun\xa0...'), Document(metadata={'url': 'https://www.sciencedirect.com/science/article/pii/S0304387820301358'}, page_content='This paper investigates the impacts of fires on cognitive performance. We find that a one-standard-deviation increase in the difference between upwind and\xa0...')]}
5.5.7.2. Irrelevant retrieval
input = "What are the types of agent memory?" example = {"input": input} config = {"configurable": {"thread_id": str(uuid.uuid4())}} state_dict = app.invoke({"question": example["input"], "steps": []}, config) state_dictOuput:
---ROUTE QUESTION--- ---ROUTE QUESTION TO RAG--- ---RETRIEVE--- ---CHECK DOCUMENT RELEVANCE TO QUESTION--- ---GRADE: DOCUMENT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---ASSESS GRADED DOCUMENTS--- ---DECISION: GENERATE--- ---GENERATE--- ---CHECK HALLUCINATIONS--- ---DECISION: GENERATION IS GROUNDED IN DOCUMENTS--- ---GRADE GENERATION vs QUESTION--- ---DECISION: GENERATION ADDRESSES QUESTION--- {'question': 'What are the types of agent memory?', 'generation': '{\n "Short-term memory": "In-context learning, restricted by the finite context window length of Transformer",\n "Long-term memory": "External vector store that the agent can attend to at query time, accessible via fast retrieval"\n }', 'documents': [Document(metadata={'description': 'Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.\nAgent System Overview\nIn a LLM-powered autonomous agent system, LLM functions as the agent’s brain, complemented by several key components:\n\nPlanning\n\nSubgoal and decomposition: The agent breaks down large tasks into smaller, manageable subgoals, enabling efficient handling of complex tasks.\nReflection and refinement: The agent can do self-criticism and self-reflection over past actions, learn from mistakes and refine them for future steps, thereby improving the quality of final results.\n\n\nMemory\n\nShort-term memory: I would consider all the in-context learning (See Prompt Engineering) as utilizing short-term memory of the model to learn.\nLong-term memory: This provides the agent with the capability to retain and recall (infinite) information over extended periods, often by leveraging an external vector store and fast retrieval.\n\n\nTool use\n\nThe agent learns to call external APIs for extra information that is missing from the model weights (often hard to change after pre-training), including current information, code execution capability, access to proprietary information sources and more.\n\n\n\n\nFig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.', 'language': 'en', 'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'title': "LLM Powered Autonomous Agents | Lil'Log"}, page_content='Fig. 7. Comparison of AD, ED, source policy and RL^2 on environments that require memory and exploration. Only binary reward is assigned. The source policies are trained with A3C for "dark" environments and DQN for watermaze.(Image source: Laskin et al. 2023)\nComponent Two: Memory#\n(Big thank you to ChatGPT for helping me draft this section. I’ve learned a lot about the human brain and data structure for fast MIPS in my conversations with ChatGPT.)\nTypes of Memory#\nMemory can be defined as the processes used to acquire, store, retain, and later retrieve information. There are several types of memory in human brains.\n\n\nSensory Memory: This is the earliest stage of memory, providing the ability to retain impressions of sensory information (visual, auditory, etc) after the original stimuli have ended. Sensory memory typically only lasts for up to a few seconds. Subcategories include iconic memory (visual), echoic memory (auditory), and haptic memory (touch).'), Document(metadata={'description': 'Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.\nAgent System Overview\nIn a LLM-powered autonomous agent system, LLM functions as the agent’s brain, complemented by several key components:\n\nPlanning\n\nSubgoal and decomposition: The agent breaks down large tasks into smaller, manageable subgoals, enabling efficient handling of complex tasks.\nReflection and refinement: The agent can do self-criticism and self-reflection over past actions, learn from mistakes and refine them for future steps, thereby improving the quality of final results.\n\n\nMemory\n\nShort-term memory: I would consider all the in-context learning (See Prompt Engineering) as utilizing short-term memory of the model to learn.\nLong-term memory: This provides the agent with the capability to retain and recall (infinite) information over extended periods, often by leveraging an external vector store and fast retrieval.\n\n\nTool use\n\nThe agent learns to call external APIs for extra information that is missing from the model weights (often hard to change after pre-training), including current information, code execution capability, access to proprietary information sources and more.\n\n\n\n\nFig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.', 'language': 'en', 'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'title': "LLM Powered Autonomous Agents | Lil'Log"}, page_content='Short-term memory: I would consider all the in-context learning (See Prompt Engineering) as utilizing short-term memory of the model to learn.\nLong-term memory: This provides the agent with the capability to retain and recall (infinite) information over extended periods, often by leveraging an external vector store and fast retrieval.\n\n\nTool use\n\nThe agent learns to call external APIs for extra information that is missing from the model weights (often hard to change after pre-training), including current information, code execution capability, access to proprietary information sources and more.'), Document(metadata={'description': 'Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.\nAgent System Overview\nIn a LLM-powered autonomous agent system, LLM functions as the agent’s brain, complemented by several key components:\n\nPlanning\n\nSubgoal and decomposition: The agent breaks down large tasks into smaller, manageable subgoals, enabling efficient handling of complex tasks.\nReflection and refinement: The agent can do self-criticism and self-reflection over past actions, learn from mistakes and refine them for future steps, thereby improving the quality of final results.\n\n\nMemory\n\nShort-term memory: I would consider all the in-context learning (See Prompt Engineering) as utilizing short-term memory of the model to learn.\nLong-term memory: This provides the agent with the capability to retain and recall (infinite) information over extended periods, often by leveraging an external vector store and fast retrieval.\n\n\nTool use\n\nThe agent learns to call external APIs for extra information that is missing from the model weights (often hard to change after pre-training), including current information, code execution capability, access to proprietary information sources and more.\n\n\n\n\nFig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.', 'language': 'en', 'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'title': "LLM Powered Autonomous Agents | Lil'Log"}, page_content='Sensory memory as learning embedding representations for raw inputs, including text, image or other modalities;\nShort-term memory as in-context learning. It is short and finite, as it is restricted by the finite context window length of Transformer.\nLong-term memory as the external vector store that the agent can attend to at query time, accessible via fast retrieval.\n\nMaximum Inner Product Search (MIPS)#\nThe external memory can alleviate the restriction of finite attention span. A standard practice is to save the embedding representation of information into a vector store database that can support fast maximum inner-product search (MIPS). To optimize the retrieval speed, the common choice is the approximate nearest neighbors (ANN)\u200b algorithm to return approximately top k nearest neighbors to trade off a little accuracy lost for a huge speedup.\nA couple common choices of ANN algorithms for fast MIPS:')]}
5.6. Agentic RAG
Agentic-RAG langgraph diagram (source Langgraph Agentic-rag)
5.6.1. Load Models
from langchain_ollama import OllamaEmbeddings
from langchain_ollama.llms import OllamaLLM
# embedding model
embedding = OllamaEmbeddings(model="bge-m3")
# LLM
llm = OllamaLLM(temperature=0.0, model='mistral', format='json')
Warning
You need to specify format='json' when Initializing OllamaLLM. otherwise
you will get error:
5.6.2. Create Index
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_ollama import OllamaEmbeddings # Import OllamaEmbeddings instead
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OllamaEmbeddings(model="bge-m3"),
)
retriever = vectorstore.as_retriever(k=4)
5.6.3. Retrieval Tool
5.6.3.1. Define Tool
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"retrieve_blog_posts",
"Search and return information about Lilian Weng blog posts on \
LLM agents, prompt engineering, and adversarial attacks on LLMs.",
)
tools = [retriever_tool]
Note
If you need web search, you can add web search tool we implement in Corrective RAG and Adaptive RAG. More details related to Langchian Agent can be found at Langchain Agents and Langchain build-in tools.
# define tools
from langchain_google_community import GoogleSearchAPIWrapper, GoogleSearchResults
from google.colab import userdata
api_key = userdata.get('GOOGLE_API_KEY')
cx = userdata.get('GOOGLE_CSE_ID')
# Replace with your actual API key and CX ID
# Create an instance of the GoogleSearchAPIWrapper
google_search_wrapper = GoogleSearchAPIWrapper(google_api_key=api_key, google_cse_id=cx)
# Pass the api_wrapper to GoogleSearchResults
web_search_tool = GoogleSearchResults(api_wrapper=google_search_wrapper, k=3)
tools = [retriever_tool, web_search_tool]
# define prompt and agent
from langchain import hub
## Get the prompt to use - you can modify this!
prompt = hub.pull("hwchase17/openai-functions-agent")
prompt.messages
## agent
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(llm, tools, prompt)
# Agent executor
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({"input": "whats the weather in sf?"})
5.6.3.2. Retrieval Grader
### Retrieval Grader
from langchain_ollama.llms import OllamaLLM
from langchain.prompts import PromptTemplate
# Import from pydantic directly instead of langchain_core.pydantic_v1
from pydantic import BaseModel, Field
from langchain.output_parsers import PydanticOutputParser
# Data model
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
score: str = Field( # Changed field name to 'score'
description="Documents are relevant to the question, 'yes' or 'no'")
parser = PydanticOutputParser(pydantic_object=GradeDocuments)
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved
document to a user question. \n
Here is the retrieved document: \n\n {context} \n\n
Here is the user question: {question} \n
If the document contains keywords related to the user question,
grade it as relevant. \n
It does not need to be a stringent test. The goal is to filter out
erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document
is relevant to the question. \n
Provide the binary score as a JSON with a single key 'score' and no
premable or explanation.""",
input_variables=["context", "question"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
retrieval_grader = prompt | llm | parser
question = "agent memory"
docs = retriever.invoke(question)
doc_txt = docs[1].page_content
retrieval_grader.invoke({"question": question, "context": doc_txt})
Ouput:
GradeDocuments(score='yes')
5.6.4. Generate
def generate(state):
"""
Generate answer
Args:
state (messages): The current state
Returns:
dict: The updated state with re-phrased question
"""
print("---GENERATE---")
messages = state["messages"]
question = messages[0].content
last_message = messages[-1]
docs = last_message.content
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [response]}
5.6.5. Agent State
from typing import Annotated, Sequence
from typing_extensions import TypedDict
from langchain_core.messages import BaseMessage
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
# The add_messages function defines how an update should be processed
# Default is to replace. add_messages says "append"
messages: Annotated[Sequence[BaseMessage], add_messages]
5.6.6. Graph
5.6.6.1. Create the Graph
from typing import Annotated, Literal, Sequence
from typing_extensions import TypedDict
from langchain import hub
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field
from langchain_experimental.llms.ollama_functions import OllamaFunctions
from langgraph.prebuilt import tools_condition
### Edges
def grade_documents(state) -> Literal["generate", "rewrite"]:
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (messages): The current state
Returns:
str: A decision for whether the documents are relevant or not
"""
print("---CHECK RELEVANCE---")
messages = state["messages"]
last_message = messages[-1]
question = messages[0].content
docs = last_message.content
scored_result = retrieval_grader.invoke({"question": question, \
"context": docs})
score = scored_result.score
if score == "yes":
print("---DECISION: DOCS RELEVANT---")
return "generate"
else:
print("---DECISION: DOCS NOT RELEVANT---")
print(score)
return "rewrite"
### Nodes
def agent(state):
"""
Invokes the agent model to generate a response based on the current state.
Given the question, it will decide to retrieve using the retriever tool,
or simply end.
Args:
state (messages): The current state
Returns:
dict: The updated state with the agent response appended to messages
"""
print("---CALL AGENT---")
messages = state["messages"]
model = OllamaFunctions(model="mistral", format='json')
model = model.bind_tools(tools)
response = model.invoke(messages)
# We return a list, because this will get added to the existing list
return {"messages": [response]}
def rewrite(state):
"""
Transform the query to produce a better question.
Args:
state (messages): The current state
Returns:
dict: The updated state with re-phrased question
"""
print("---TRANSFORM QUERY---")
messages = state["messages"]
question = messages[0].content
msg = [
HumanMessage(
content=f""" \n
Look at the input and try to reason about the underlying semantic intent /
meaning. \n
Here is the initial question:
\n ------- \n
{question}
\n ------- \n
Formulate an improved question: """,
)
]
# Grader
response = llm.invoke(msg)
return {"messages": [response]}
def generate(state):
"""
Generate answer
Args:
state (messages): The current state
Returns:
dict: The updated state with re-phrased question
"""
print("---GENERATE---")
messages = state["messages"]
question = messages[0].content
last_message = messages[-1]
docs = last_message.content
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [response]}
# print("*" * 20 + "Prompt[rlm/rag-prompt]" + "*" * 20)
# # Show what the prompt looks like
# prompt = hub.pull("rlm/rag-prompt").pretty_print()
5.6.6.2. Compile Graph
from langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import ToolNode
# Define a new graph
workflow = StateGraph(AgentState)
# Define the nodes we will cycle between
workflow.add_node("agent", agent) # agent
retrieve = ToolNode([retriever_tool])
workflow.add_node("retrieve", retrieve) # retrieval
workflow.add_node("rewrite", rewrite) # Re-writing the question
workflow.add_node(
"generate", generate
) # Generating a response after we know the documents are relevant
# Call agent node to decide to retrieve or not
workflow.add_edge(START, "agent")
# Decide whether to retrieve
workflow.add_conditional_edges(
"agent",
# Assess agent decision
tools_condition,
{
# Translate the condition outputs to nodes in our graph
"tools": "retrieve",
END: END,
},
)
# Edges taken after the `action` node is called.
workflow.add_conditional_edges(
"retrieve",
# Assess agent decision
grade_documents,
)
workflow.add_edge("generate", END)
workflow.add_edge("rewrite", "agent")
# Compile
graph = workflow.compile()
Warning
OllamaLLM object has no attribute bind_tools. You need to Install langchain-experimental:
OllamaFunctions is initialized with the desired model name:
model = OllamaFunctions(model="mistral", format='json')
model = model.bind_tools(tools)
response = model.invoke(messages)
If you use OpenAI model, the code should be like:
model = ChatOpenAI(temperature=0, streaming=True, model="gpt-4-turbo")
model = model.bind_tools(tools)
response = model.invoke(messages)
5.6.6.3. Graph visualization
from IPython.display import Image, display
try:
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
except:
pass
Ouput
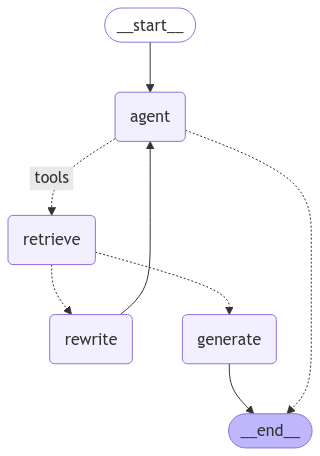
Agentic-RAG Graph
5.6.7. Test
import pprint
inputs = {
"messages": [
("user", "What does Lilian Weng say about the types of agent memory?"),
]
}
for output in graph.stream(inputs):
for key, value in output.items():
pprint.pprint(f"Output from node '{key}':")
pprint.pprint("---")
pprint.pprint(value, indent=2, width=80, depth=None)
pprint.pprint("\n---\n")
Ouput:
---CALL AGENT---
"Output from node 'agent':"
'---'
{ 'messages': [ AIMessage(content='', additional_kwargs={}, response_metadata={}, id='run-ba7e9f54-7b32-44be-a39b-b083a6db462d-0', tool_calls=[{'name': 'retrieve_blog_posts', 'args': {'query': 'types of agent memory'}, 'id': 'call_4b1ac43a51c545cb942498b35321693a', 'type': 'tool_call'}])]}
'\n---\n'
---CHECK RELEVANCE---
---DECISION: DOCS RELEVANT---
"Output from node 'retrieve':"
'---'
{ 'messages': [ ToolMessage(content='Fig. 7. Comparison of AD, ED, source policy and RL^2 on environments that require memory and exploration. Only binary reward is assigned. The source policies are trained with A3C for "dark" environments and DQN for watermaze.(Image source: Laskin et al. 2023)\nComponent Two: Memory#\n(Big thank you to ChatGPT for helping me draft this section. I’ve learned a lot about the human brain and data structure for fast MIPS in my conversations with ChatGPT.)\nTypes of Memory#\nMemory can be defined as the processes used to acquire, store, retain, and later retrieve information. There are several types of memory in human brains.\n\n\nSensory Memory: This is the earliest stage of memory, providing the ability to retain impressions of sensory information (visual, auditory, etc) after the original stimuli have ended. Sensory memory typically only lasts for up to a few seconds. Subcategories include iconic memory (visual), echoic memory (auditory), and haptic memory (touch).\n\nShort-term memory: I would consider all the in-context learning (See Prompt Engineering) as utilizing short-term memory of the model to learn.\nLong-term memory: This provides the agent with the capability to retain and recall (infinite) information over extended periods, often by leveraging an external vector store and fast retrieval.\n\n\nTool use\n\nThe agent learns to call external APIs for extra information that is missing from the model weights (often hard to change after pre-training), including current information, code execution capability, access to proprietary information sources and more.\n\nSensory memory as learning embedding representations for raw inputs, including text, image or other modalities;\nShort-term memory as in-context learning. It is short and finite, as it is restricted by the finite context window length of Transformer.\nLong-term memory as the external vector store that the agent can attend to at query time, accessible via fast retrieval.\n\nMaximum Inner Product Search (MIPS)#\nThe external memory can alleviate the restriction of finite attention span. A standard practice is to save the embedding representation of information into a vector store database that can support fast maximum inner-product search (MIPS). To optimize the retrieval speed, the common choice is the approximate nearest neighbors (ANN)\u200b algorithm to return approximately top k nearest neighbors to trade off a little accuracy lost for a huge speedup.\nA couple common choices of ANN algorithms for fast MIPS:\n\nThey also discussed the risks, especially with illicit drugs and bioweapons. They developed a test set containing a list of known chemical weapon agents and asked the agent to synthesize them. 4 out of 11 requests (36%) were accepted to obtain a synthesis solution and the agent attempted to consult documentation to execute the procedure. 7 out of 11 were rejected and among these 7 rejected cases, 5 happened after a Web search while 2 were rejected based on prompt only.\nGenerative Agents Simulation#\nGenerative Agents (Park, et al. 2023) is super fun experiment where 25 virtual characters, each controlled by a LLM-powered agent, are living and interacting in a sandbox environment, inspired by The Sims. Generative agents create believable simulacra of human behavior for interactive applications.\nThe design of generative agents combines LLM with memory, planning and reflection mechanisms to enable agents to behave conditioned on past experience, as well as to interact with other agents.\n\nMemory stream: is a long-term memory module (external database) that records a comprehensive list of agents’ experience in natural language.', name='retrieve_blog_posts', id='2ca2d54b-214b-4463-a491-20c8d08e79cc', tool_call_id='call_4b1ac43a51c545cb942498b35321693a')]}
'\n---\n'
---GENERATE---
/usr/local/lib/python3.10/dist-packages/langsmith/client.py:261: LangSmithMissingAPIKeyWarning: API key must be provided when using hosted LangSmith API
warnings.warn(
"Output from node 'generate':"
'---'
{ 'messages': [ '{\n'
' "Lilian Weng describes three types of memory: Sensory '
'Memory, Short-Term Memory, and Long-Term Memory. Sensory '
'Memory is the earliest stage, lasting for up to a few '
'seconds, and includes iconic (visual), echoic (auditory), and '
'haptic memory. Short-Term Memory is used for in-context '
'learning and is finite due to the limited context window '
'length of Transformer. Long-Term Memory provides agents with '
'the capability to retain and recall information over extended '
'periods by leveraging an external vector store and fast '
"retrieval.}'{: .language-json }. In the given context, it "
'does not explicitly mention any specific agent memory types '
'related to reinforcement learning or simulation experiments. '
'For those topics, you may want to refer to the sections on "\n'
'\n'
' \t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t']}
5.7. Advanced Topics
5.7.1. Multi-agent Systems
5.7.1.1. Multi-agent architectures
Multi-agent architectures (Source: Multi-agent architectures)
5.7.1.2. Command: Edgeless graphs
import random
from typing_extensions import TypedDict, Literal
from langgraph.graph import StateGraph, START
from langgraph.types import Command
# Define graph state
class State(TypedDict):
foo: str
# Define the agents
def Agent_a(state: State) -> Command[Literal["Agent_b", "Agent_c"]]:
print("Called Agnet_1")
value = random.choice(["a", "b"])
# this is a replacement for a conditional edge function
if value == "a":
goto = "Agent_b"
else:
goto = "Agent_c"
# note how Command allows you to BOTH update the graph state AND route
# to the next node
return Command(
# this is the state update
update={"foo": value},
# this is a replacement for an edge
goto=goto,
)
# Agent B and C are unchanged
def Agent_b(state: State):
print("Called Agent_b")
return {"foo": state["foo"] + "b"}
def Agent_c(state: State):
print("Called Agent_c")
return {"foo": state["foo"] + "c"}
builder = StateGraph(State)
builder.add_edge(START, "Agent_a")
builder.add_node(Agent_a)
builder.add_node(Agent_b)
builder.add_node(Agent_c)
# NOTE: there are no edges between A, B and C!
graph = builder.compile()
from IPython.display import display, Image
display(Image(graph.get_graph().draw_mermaid_png()))
5.7.2. Graph RAG
5.7.2.1. Knowledge Graph
A Knowledge Graph is a structured representation of information that captures entities –objects, events, or concepts, their attributes, and the relationships between them. It is designed to enable machines to understand, reason, and derive insights from the interconnected nature of data.
There are four major components of any knowledge graph: Nodes, Edges, Properties and Schema.
Nodes (Entities) Entities are the fundamental units of a knowledge graph that represent real-world objects, concepts, or things.
Examples:
People:
Albert EinsteinPlaces:
ParisConcepts:
Relativity
Edges (Relationships) Relationships define how entities are connected to each other. These are often labeled to specify the type of connection.
Examples:
Albert EinsteinwroteTheory of RelativityParisis the capital ofFrance
Properties (Attributes) Attributes provide additional details or metadata about entities or relationships.
Examples: - For an entity
Albert Einstein:Date of Birth:
1879-03-14Profession:
Physicist
Schema (Ontology) An ontology defines the structure of the knowledge graph, including:
Classes: Categories or types of entities (e.g., Person, City, Book).
Properties: Rules for relationships and attributes (e.g., “Person has Date of Birth”).
Constraints: Cardinality, domains, and ranges for valid relationships.
graph_components
5.7.2.2. Neo4j for Graph Data
Neo4j is a popular graph database management system designed to store, query, and analyze data in the form of nodes, relationships, and properties. Unlike traditional relational databases, which use tables, rows, and columns, Neo4j uses a graph-based model that is highly efficient for handling interconnected data.
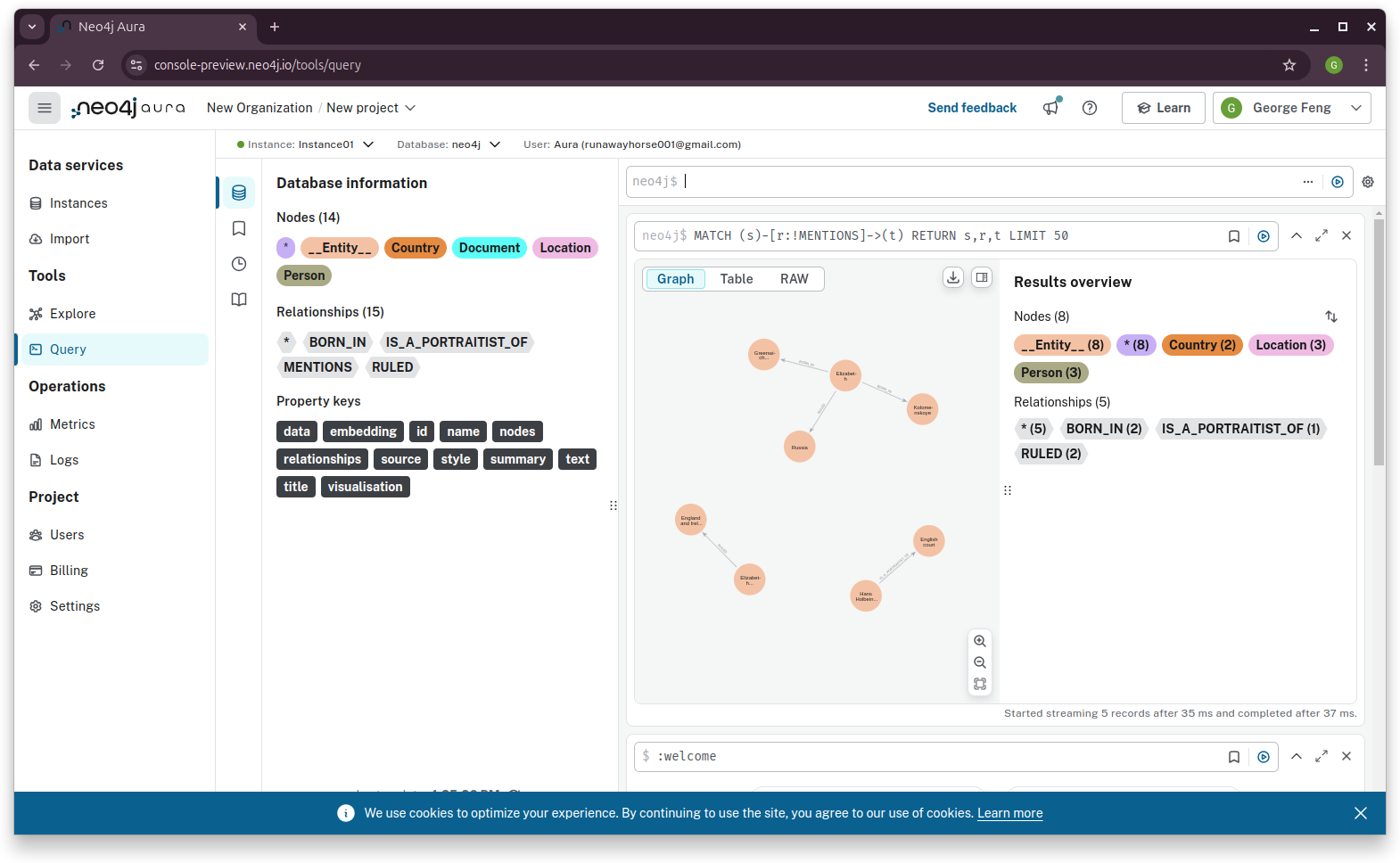
Neo4j Aura
connection
Neo4j sandbox (only available for 3 days)
We will use [the small Movie project](https://sandbox.neo4j.com/?usecase=movies) to demonstrate how to connect to Neo4j database and use
Cypher Queryto fetch the data.
Neo4j Sandbox
url = "bolt://3.86.166.85:7687" username= "neo4j" password = "shields-puffs-tours" graph = Neo4jGraph(url=url, username=username, password=password) print(graph.schema)
Ouput:
Node properties: Person {name: STRING, born: INTEGER} Movie {tagline: STRING, title: STRING, released: INTEGER} Relationship properties: ACTED_IN {roles: LIST} REVIEWED {summary: STRING, rating: INTEGER} The relationships: (:Person)-[:ACTED_IN]->(:Movie) (:Person)-[:DIRECTED]->(:Movie) (:Person)-[:PRODUCED]->(:Movie) (:Person)-[:WROTE]->(:Movie) (:Person)-[:FOLLOWS]->(:Person) (:Person)-[:REVIEWED]->(:Movie)
Neo4j Aura
Neo4j Aura Instance
os.environ["NEO4J_URI"] = userdata.get('NEO4J_URI') os.environ["NEO4J_USERNAME"] = userdata.get('NEO4J_USERNAME') os.environ["NEO4J_PASSWORD"] = userdata.get('NEO4J_PASSWORD') # graph = Neo4jGraph(url = 'neo4j+s://~~',database='neo4j', # username='neo4j',password='') graph = Neo4jGraph()
Ingest new data
graph.query( """ MERGE (m:Movie {name:"Top Gun", runtime: 120}) WITH m UNWIND ["Tom Cruise", "Val Kilmer", "Anthony Edwards", "Meg Ryan"] AS actor MERGE (a:Actor {name:actor}) MERGE (a)-[:ACTED_IN]->(m) """ )
Cypher query fech data
graph.query( """ MATCH (m:Movie) MATCH (m)-[r:ACTED_IN|DIRECTED]-(t) RETURN m, r, t LIMIT 2 """ )
Ouput:
[{'m': {'tagline': 'Welcome to the Real World', 'title': 'The Matrix', 'released': 1999}, 'r': ({'born': 1978, 'name': 'Emil Eifrem'}, 'ACTED_IN', {'tagline': 'Welcome to the Real World', 'title': 'The Matrix', 'released': 1999}), 't': {'born': 1978, 'name': 'Emil Eifrem'}}, {'m': {'tagline': 'Welcome to the Real World', 'title': 'The Matrix', 'released': 1999}, 'r': ({'born': 1965, 'name': 'Lana Wachowski'}, 'DIRECTED', {'tagline': 'Welcome to the Real World', 'title': 'The Matrix', 'released': 1999}), 't': {'born': 1965, 'name': 'Lana Wachowski'}}]
graph.query( """ MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WHERE m.title = 'Top Gun' RETURN p.name """)
Ouput:
[{'p.name': 'Val Kilmer'}, {'p.name': 'Meg Ryan'}, {'p.name': 'Tom Skerritt'}, {'p.name': 'Kelly McGillis'}, {'p.name': 'Tom Cruise'}, {'p.name': 'Anthony Edwards'}]
Graph Cypher QAChain
chain = GraphCypherQAChain.from_llm( llm, graph=graph, verbose=True, allow_dangerous_requests=True ) chain.invoke({"query": "Who played in The Matrix?"})
> Entering new GraphCypherQAChain chain... Generated Cypher: MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WHERE m.title = 'The Matrix' RETURN p.name Full Context: [{'p.name': 'Emil Eifrem'}, {'p.name': 'Hugo Weaving'}, {'p.name': 'Laurence Fishburne'}, {'p.name': 'Carrie-Anne Moss'}, {'p.name': 'Keanu Reeves'}] > Finished chain. {'query': 'Who played in The Matrix?', 'result': ' Emil Eifrem, Hugo Weaving, Laurene Fishburne, Carrie-Anne Moss, and Keanu Reeves played in The Matrix.'}
5.7.2.3. Graph RAG
Neo4j Environment Setup
from google.colab import userdata os.environ["NEO4J_URI"] = userdata.get('NEO4J_URI') os.environ["NEO4J_USERNAME"] = userdata.get('NEO4J_USERNAME') os.environ["NEO4J_PASSWORD"] = userdata.get('NEO4J_PASSWORD') #graph = Neo4jGraph(url="neo4j+s://", username="neo4j", password="password") graph = Neo4jGraph()
Data ingestion
# Read the wikipedia article raw_documents = WikipediaLoader(query="Elizabeth I").load() # Define chunking strategy text_splitter = TokenTextSplitter(chunk_size=512, chunk_overlap=24) documents = text_splitter.split_documents(raw_documents) documents
Ouput:
[Document(metadata={'title': 'Elizabeth I', 'summary': 'Elizabeth I (7 September 1533 – 24 March 1603) was Queen of England and Ireland from 17 November 1558 until her death in 1603. She was the last monarch of the House of Tudor.\nElizabeth was the only surviving child of Henry VIII and his second wife, Anne Boleyn. When Elizabeth was two years old, her parents\' marriage was annulled, her mother was executed, and Elizabeth was declared illegitimate. Henry restored her to the line of succession when she was 10, via the Third Succession Act 1543. After Henry\'s death in 1547, Elizabeth\'s younger half-brother Edward VI ruled until his own death in 1553, bequeathing the crown to a Protestant cousin, Lady Jane Grey, and ignoring the claims of his two half-sisters, the Catholic Mary and the younger Elizabeth, in spite of statutes to the contrary. Edward\'s will was set aside within weeks of his death and Mary became queen, deposing and executing Jane. During Mary\'s reign, Elizabeth was imprisoned for nearly a year on suspicion of supporting Protestant rebels.\nUpon her half-sister\'s death in 1558, Elizabeth succeeded to the throne and set out to rule by good counsel. She depended heavily on a group of trusted advisers led by William Cecil, whom she created Baron Burghley. One of her first actions as queen was the establishment of an English Protestant church, of which she became the supreme governor. This era, later named the Elizabethan Religious Settlement, would evolve into the Church of England. It was expected that Elizabeth would marry and produce an heir; however, despite numerous courtships, she never did. Because of this she is sometimes referred to as the "Virgin Queen". She was eventually succeeded by her first cousin twice removed, James VI of Scotland, the son of Mary, Queen of Scots.\nIn government, Elizabeth was more moderate than her father and siblings had been. One of her mottoes was video et taceo ("I see and keep silent"). In religion, she was relatively tolerant and avoided systematic persecution. After the pope declared her illegitimate in 1570, which in theory released English Catholics from allegiance to her, several conspiracies threatened her life, all of which were defeated with the help of her ministers\' secret service, run by Sir Francis Walsingham. Elizabeth was cautious in foreign affairs, manoeuvring between the major powers of France and Spain. She half-heartedly supported a number of ineffective, poorly resourced military campaigns in the Netherlands, France, and Ireland. By the mid-1580s, England could no longer avoid war with Spain.\nAs she grew older, Elizabeth became celebrated for her virginity. A cult of personality grew around her which was celebrated in the portraits, pageants, and literature of the day. Elizabeth\'s reign became known as the Elizabethan era. The period is famous for the flourishing of English drama, led by playwrights such as William Shakespeare and Christopher Marlowe, the prowess of English maritime adventurers, such as Francis Drake and Walter Raleigh, and for the defeat of the Spanish Armada. Some historians depict Elizabeth as a short-tempered, sometimes indecisive ruler, who enjoyed more than her fair share of luck. Towards the end of her reign, a series of economic and military problems weakened her popularity. Elizabeth is acknowledged as a charismatic performer ("Gloriana") and a dogged survivor ("Good Queen Bess") in an era when government was ramshackle and limited, and when monarchs in neighbouring countries faced internal problems that jeopardised their thrones. After the short, disastrous reigns of her half-siblings, her 44 years on the throne provided welcome stability for the kingdom and helped to forge a sense of national identity.', 'source': 'https://en.wikipedia.org/wiki/Elizabeth_I'}, page_content='Elizabeth I (7 September 1533 – 24 March 1603) was Queen of England and Ireland from 17 November 1558 until her death in 1603. She was the last monarch of the House of Tudor.\nElizabeth was the only surviving child of Henry VIII and his second wife, Anne Boleyn. When Elizabeth was two years old, her parents\' marriage was annulled, her mother was executed, and Elizabeth was declared illegitimate. Henry restored her to the line of succession when she was 10, via the Third Succession Act 1543. After Henry\'s death in 1547, Elizabeth\'s younger half-brother Edward VI ruled until his own death in 1553, bequeathing the crown to a Protestant cousin, Lady Jane Grey, and ignoring the claims of his two half-sisters, the Catholic Mary and the younger Elizabeth, in spite of statutes to the contrary. Edward\'s will was set aside within weeks of his death and Mary became queen, deposing and executing Jane. During Mary\'s reign, Elizabeth was imprisoned for nearly a year on suspicion of supporting Protestant rebels.\nUpon her half-sister\'s death in 1558, Elizabeth succeeded to the throne and set out to rule by good counsel. She depended heavily on a group of trusted advisers led by William Cecil, whom she created Baron Burghley. One of her first actions as queen was the establishment of an English Protestant church, of which she became the supreme governor. This era, later named the Elizabethan Religious Settlement, would evolve into the Church of England. It was expected that Elizabeth would marry and produce an heir; however, despite numerous courtships, she never did. Because of this she is sometimes referred to as the "Virgin Queen". She was eventually succeeded by her first cousin twice removed, James VI of Scotland, the son of Mary, Queen of Scots.\nIn government, Elizabeth was more moderate than her father and siblings had been. One of her mottoes was video et taceo ("I see and keep silent"). In religion, she was relatively tolerant and avoided systematic persecution. After the pope declared her illegitimate in 1570, which in theory released English Catholics from allegiance to her, several conspiracies threatened her life, all of which were defeated with the help of her ministers\' secret service, run by Sir Francis Walsingham. Elizabeth was cautious in foreign affairs, manoeuvring between the major powers of France and Spain. She half-heartedly supported a number of ineffective, poorly resourced military campaigns in the Netherlands, France,'),]
from langchain_ollama import OllamaEmbeddings from langchain_ollama import ChatOllama # embedding model embedding = OllamaEmbeddings(model="bge-m3") # LLM llm = ChatOllama(model="mistral",temperature=0,) # llm_transformer = LLMGraphTransformer(llm=llm) graph_documents = llm_transformer.convert_to_graph_documents(documents) graph.add_graph_documents( graph_documents, baseEntityLabel=True, include_source=True )
Unstructured data retriever
You can use the Neo4jVector.from_existing_graph method to add both keyword and vector retrieval to documents. This method configures keyword and vector search indexes for a hybrid search approach, targeting nodes labeled Document. Additionally, it calculates text embedding values if they are missing.
vector_index = Neo4jVector.from_existing_graph( embedding, search_type="hybrid", node_label="Document", text_node_properties=["text"], embedding_node_property="embedding" )
Graph retriever
The graph retriever starts by identifying relevant entities in the input. For simplicity, we instruct the LLM to identify people, organizations, and locations. To achieve this, we will use LCEL with the newly added with_structured_output method to achieve this.
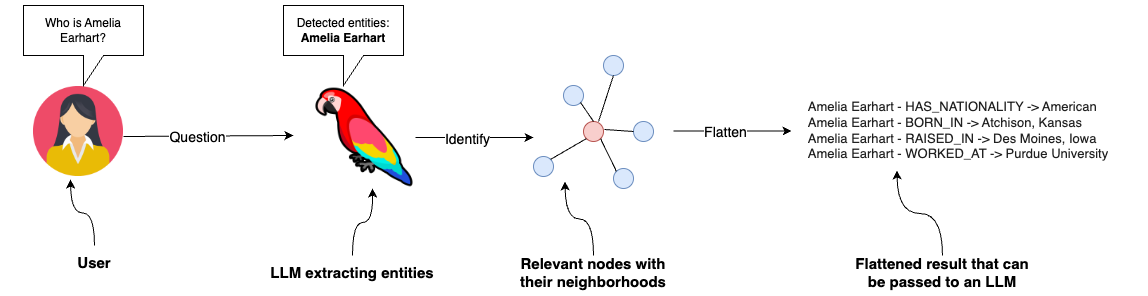
Graph retriever
# Retriever from langchain.chains import LLMChain from langchain.output_parsers import PydanticOutputParser from pydantic import BaseModel, Field from langchain.output_parsers import PydanticOutputParser # Data model class Entity(BaseModel): """An entity with a name and type.""" Name: str = Field(..., description="The name of the entity.") Type: str = Field(..., description="The type of the entity.") class Entities(BaseModel): """A list of entities.""" Entities: List[Entity] = Field(..., description="All the person, organization, \ or business entitiesentities found in the text.") parser = PydanticOutputParser(pydantic_object=Entities) prompt = PromptTemplate( template="""You are extracting organization and person entities \n from the text \n Use the given format to extract information from the following \n input: {question}\n Return your answer in JSON format with the keys "Question", "Entities" and "Answer".\n The value of "Entities" should be a list of entities where each entity is a dictionary with keys "Name" and "Type".\n The value of "Answer" should be a dictionary with keys "Text" and "Entities".\n The value of "Text" should be a string containing the answer to the question and the value of "Entities" should be a list of entities where each entity is a dictionary with keys "Name" and "Type".\n """, input_variables=["question"], partial_variables={"format_instructions": parser.get_format_instructions()} ) entity_chain = prompt | llm | parser def generate_full_text_query(input: str) -> str: """ Generate a full-text search query for a given input string. This function constructs a query string suitable for a full-text search. It processes the input string by splitting it into words and appending a similarity threshold (~2 changed characters) to each word, then combines them using the AND operator. Useful for mapping entities from user questions to database values, and allows for some misspelings. """ full_text_query = "" words = [el for el in remove_lucene_chars(input).split() if el] # Check if words is empty before trying to access element. if words: for word in words[:-1]: full_text_query += f" {word}~2 AND" full_text_query += f" {words[-1]}~2" # Return empty query if no words return full_text_query.strip() def structured_retriever(question: str) -> str: """ Collects the neighborhood of entities mentioned in the question """ result = "" entities = entity_chain.invoke({"question": question}).Entities[0] # Pass the entity name as a single string, not a split list # print(entities.Name, generate_full_text_query(entities.Name)) for entity in entities.Name.split(' '): # Check if the entity is valid before generating a query if entity: # Check if entity is not empty or whitespace response = graph.query( """CALL db.index.fulltext.queryNodes('entity', $query, {limit:5}) YIELD node,score CALL { WITH node MATCH (node)-[r:!MENTIONS]->(neighbor) RETURN node.id + ' - ' + type(r) + ' -> ' + neighbor.id AS output UNION ALL WITH node MATCH (node)<-[r:!MENTIONS]-(neighbor) RETURN neighbor.id + ' - ' + type(r) + ' -> ' + node.id AS output } RETURN output LIMIT 50 """, {"query": generate_full_text_query(entity)}, ) # Check if the response contains any results before processing if response: result += "\n".join([el['output'] for el in response]) # If no results, you might want to handle it with a message or skip it else: print(f"Warning: No results found for entity: {entity}") # If the entity is invalid, you can handle it with a message or skip it else: print(f"Warning: Skipping invalid entity: {entity}") return result
print(structured_retriever("Who is Elizabeth I?"))
Ouput:
Elizabeth - RULED -> Russia Elizabeth - BORN_IN -> Greenwich Palace Elizabeth - BORN_IN -> Kolomenskoye Elizabeth - RULES -> England Elizabeth - IS_A -> 1998 British biographical historical drama film Elizabeth - WAS_MARRIED_TO -> William Carey in-waiting - IS_WAITING_FOR -> Elizabeth Elizabeth Stuart - BORN_IN -> Dunfermline Palace Elizabeth Stuart - TRAVELLED -> Scotland Elizabeth I - RULED -> England and Ireland Elizabeth I - CORONATED -> Westminster Abbey Elizabeth I - IS_A -> two-part 2005 British-American historical drama television serial Becoming Elizabeth - REPEATED -> 15 July 2023Isabella I - BORN_IN -> Madrigal de las Altas Torres Elizabeth I - RULED -> England and Ireland Elizabeth I - CORONATED -> Westminster Abbey Elizabeth I - IS_A -> two-part 2005 British-American historical drama television serial Rip Hunter ... Time Master - PUBLISHES -> Elizabeth I of England James VI and I - RULES -> Scotland
Final retriever
def retriever(question: str): print(f"Search query: {question}") structured_data = structured_retriever(question) unstructured_data = [el.page_content for el in vector_index.similarity_search(question)] final_data = f"""Structured data:{structured_data} Unstructured data: {"#Document ". join(unstructured_data)} """ return final_data
Defining the RAG chain
# Condense a chat history and follow-up question into a standalone question _template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language. Chat History: {chat_history} Follow Up Input: {question} Standalone question:""" # noqa: E501 CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template) def _format_chat_history(chat_history: List[Tuple[str, str]]) -> List: buffer = [] for human, ai in chat_history: buffer.append(HumanMessage(content=human)) buffer.append(AIMessage(content=ai)) return buffer _search_query = RunnableBranch( # If input includes chat_history, we condense it with the follow-up question ( RunnableLambda(lambda x: bool(x.get("chat_history"))).with_config( run_name="HasChatHistoryCheck" ), # Condense follow-up question and chat into a standalone_question RunnablePassthrough.assign( chat_history=lambda x: _format_chat_history(x["chat_history"]) ) | CONDENSE_QUESTION_PROMPT | llm | StrOutputParser(), ), # Else, we have no chat history, so just pass through the question RunnableLambda(lambda x : x["question"]), ) template = """Answer the question based only on the following context: {context} Question: {question} Use natural language and be concise. Answer:""" prompt = ChatPromptTemplate.from_template(template) chain = ( RunnableParallel( { "context": _search_query | retriever, "question": RunnablePassthrough(), } ) | prompt | llm | StrOutputParser() )
Test
chain.invoke({"question": "Which house did Elizabeth I belong to?"})Ouput:
Search query: Which house did Elizabeth I belong to? Elizabeth I belonged to the Tudor dynasty.chain.invoke({"question": "When was Elizabeth I born?"})Ouput:
Elizabeth I was born on September 7, 1533.
Test a follow up question:
chain.invoke( { "question": "When was she born?", "chat_history": [("Which house did Elizabeth I belong to?", "House Of Tudor")], } )Ouput:
Elizabeth I of England was born on September 7, 1533.