14. Text Mining¶
Chinese proverb
Articles showed more than intended. – Xianglong Shen
14.1. Text Collection¶
14.1.1. Image to text¶
My
img2txtfunction
def img2txt(img_dir):
"""
convert images to text
"""
import os, PythonMagick
from datetime import datetime
import PyPDF2
from PIL import Image
import pytesseract
f = open('doc4img.txt','wa')
for img in [img_file for img_file in os.listdir(img_dir)
if (img_file.endswith(".png") or
img_file.endswith(".jpg") or
img_file.endswith(".jpeg"))]:
start_time = datetime.now()
input_img = img_dir + "/" + img
print('--------------------------------------------------------------------')
print(img)
print('Converting ' + img +'.......')
print('--------------------------------------------------------------------')
# extract the text information from images
text = pytesseract.image_to_string(Image.open(input_img))
print(text)
# ouput text file
f.write( img + "\n")
f.write(text.encode('utf-8'))
print "CPU Time for converting" + img +":"+ str(datetime.now() - start_time) +"\n"
f.write( "\n-------------------------------------------------------------\n")
f.close()
Demo
I applied my img2txt function to the image in Image folder.
image_dir = r"Image"
img2txt(image_dir)
Then I got the following results:
--------------------------------------------------------------------
feng.pdf_0.png
Converting feng.pdf_0.png.......
--------------------------------------------------------------------
l I l w
Wenqiang Feng
Data Scientist
DST APPLIED ANALYTICS GROUP
Wenqiang Feng is Data Scientist for DST’s Applied Analytics Group. Dr. Feng’s responsibilities
include providing DST clients with access to cutting—edge skills and technologies, including Big
Data analytic solutions, advanced analytic and data enhancement techniques and modeling.
Dr. Feng has deep analytic expertise in data mining, analytic systems, machine learning
algorithms, business intelligence, and applying Big Data tools to strategically solve industry
problems in a cross—functional business. Before joining the DST Applied Analytics Group, Dr.
Feng holds a MA Data Science Fellow at The Institute for Mathematics and Its Applications
{IMA) at the University of Minnesota. While there, he helped startup companies make
marketing decisions based on deep predictive analytics.
Dr. Feng graduated from University of Tennessee, Knoxville with PhD in Computational
mathematics and Master’s degree in Statistics. He also holds Master’s degree in Computational
Mathematics at Missouri University of Science and Technology (MST) and Master’s degree in
Applied Mathematics at University of science and technology of China (USTC).
CPU Time for convertingfeng.pdf_0.png:0:00:02.061208
14.1.2. Image Enhnaced to text¶
My
img2txt_enhancefunction
def img2txt_enhance(img_dir,scaler):
"""
convert images files to text
"""
import numpy as np
import os, PythonMagick
from datetime import datetime
import PyPDF2
from PIL import Image, ImageEnhance, ImageFilter
import pytesseract
f = open('doc4img.txt','wa')
for img in [img_file for img_file in os.listdir(img_dir)
if (img_file.endswith(".png") or
img_file.endswith(".jpg") or
img_file.endswith(".jpeg"))]:
start_time = datetime.now()
input_img = img_dir + "/" + img
enhanced_img = img_dir + "/" +"Enhanced" + "/"+ img
im = Image.open(input_img) # the second one
im = im.filter(ImageFilter.MedianFilter())
enhancer = ImageEnhance.Contrast(im)
im = enhancer.enhance(1)
im = im.convert('1')
im.save(enhanced_img)
for scale in np.ones(scaler):
im = Image.open(enhanced_img) # the second one
im = im.filter(ImageFilter.MedianFilter())
enhancer = ImageEnhance.Contrast(im)
im = enhancer.enhance(scale)
im = im.convert('1')
im.save(enhanced_img)
print('--------------------------------------------------------------------')
print(img)
print('Converting ' + img +'.......')
print('--------------------------------------------------------------------')
# extract the text information from images
text = pytesseract.image_to_string(Image.open(enhanced_img))
print(text)
# ouput text file
f.write( img + "\n")
f.write(text.encode('utf-8'))
print "CPU Time for converting" + img +":"+ str(datetime.now() - start_time) +"\n"
f.write( "\n-------------------------------------------------------------\n")
f.close()
Demo
I applied my img2txt_enhance function to the following noised image in Enhance folder.

image_dir = r"Enhance"
pdf2txt_enhance(image_dir)
Then I got the following results:
--------------------------------------------------------------------
noised.jpg
Converting noised.jpg.......
--------------------------------------------------------------------
zHHH
CPU Time for convertingnoised.jpg:0:00:00.135465
while the result from img2txt function is
--------------------------------------------------------------------
noised.jpg
Converting noised.jpg.......
--------------------------------------------------------------------
,2 WW
CPU Time for convertingnoised.jpg:0:00:00.133508
which is not correct.
14.1.3. PDF to text¶
My
pdf2txtfunction
def pdf2txt(pdf_dir,image_dir):
"""
convert PDF to text
"""
import os, PythonMagick
from datetime import datetime
import PyPDF2
from PIL import Image
import pytesseract
f = open('doc.txt','wa')
for pdf in [pdf_file for pdf_file in os.listdir(pdf_dir) if pdf_file.endswith(".pdf")]:
start_time = datetime.now()
input_pdf = pdf_dir + "/" + pdf
pdf_im = PyPDF2.PdfFileReader(file(input_pdf, "rb"))
npage = pdf_im.getNumPages()
print('--------------------------------------------------------------------')
print(pdf)
print('Converting %d pages.' % npage)
print('--------------------------------------------------------------------')
f.write( "\n--------------------------------------------------------------------\n")
for p in range(npage):
pdf_file = input_pdf + '[' + str(p) +']'
image_file = image_dir + "/" + pdf+ '_' + str(p)+ '.png'
# convert PDF files to Images
im = PythonMagick.Image()
im.density('300')
im.read(pdf_file)
im.write(image_file)
# extract the text information from images
text = pytesseract.image_to_string(Image.open(image_file))
#print(text)
# ouput text file
f.write( pdf + "\n")
f.write(text.encode('utf-8'))
print "CPU Time for converting" + pdf +":"+ str(datetime.now() - start_time) +"\n"
f.close()
Demo
I applied my pdf2txt function to my scaned bio pdf file in pdf folder.
pdf_dir = r"pdf"
image_dir = r"Image"
pdf2txt(pdf_dir,image_dir)
Then I got the following results:
--------------------------------------------------------------------
feng.pdf
Converting 1 pages.
--------------------------------------------------------------------
l I l w
Wenqiang Feng
Data Scientist
DST APPLIED ANALYTICS GROUP
Wenqiang Feng is Data Scientist for DST’s Applied Analytics Group. Dr. Feng’s responsibilities
include providing DST clients with access to cutting—edge skills and technologies, including Big
Data analytic solutions, advanced analytic and data enhancement techniques and modeling.
Dr. Feng has deep analytic expertise in data mining, analytic systems, machine learning
algorithms, business intelligence, and applying Big Data tools to strategically solve industry
problems in a cross—functional business. Before joining the DST Applied Analytics Group, Dr.
Feng holds a MA Data Science Fellow at The Institute for Mathematics and Its Applications
{IMA) at the University of Minnesota. While there, he helped startup companies make
marketing decisions based on deep predictive analytics.
Dr. Feng graduated from University of Tennessee, Knoxville with PhD in Computational
mathematics and Master’s degree in Statistics. He also holds Master’s degree in Computational
Mathematics at Missouri University of Science and Technology (MST) and Master’s degree in
Applied Mathematics at University of science and technology of China (USTC).
CPU Time for convertingfeng.pdf:0:00:03.143800
14.1.4. Audio to text¶
My
audio2txtfunction
def audio2txt(audio_dir):
''' convert audio to text'''
import speech_recognition as sr
r = sr.Recognizer()
f = open('doc.txt','wa')
for audio_n in [audio_file for audio_file in os.listdir(audio_dir) \
if audio_file.endswith(".wav")]:
filename = audio_dir + "/" + audio_n
# Read audio data
with sr.AudioFile(filename) as source:
audio = r.record(source) # read the entire audio file
# Google Speech Recognition
text = r.recognize_google(audio)
# ouput text file
f.write( audio_n + ": ")
f.write(text.encode('utf-8'))
f.write("\n")
print('You said: ' + text)
f.close()
Demo
I applied my audio2txt function to my audio records in audio folder.
audio_dir = r"audio"
audio2txt(audio_dir)
Then I got the following results:
You said: hello this is George welcome to my tutorial
You said: mathematics is important in daily life
You said: call me tomorrow
You said: do you want something to eat
You said: I want to speak with him
You said: nice to see you
You said: can you speak slowly
You said: have a good day
By the way, you can use my following python code to record your own audio and play with audio2txt function in Command-line python record.py "demo2.wav":
import sys, getopt
import speech_recognition as sr
audio_filename = sys.argv[1]
r = sr.Recognizer()
with sr.Microphone() as source:
r.adjust_for_ambient_noise(source)
print("Hey there, say something, I am recording!")
audio = r.listen(source)
print("Done listening!")
with open(audio_filename, "wb") as f:
f.write(audio.get_wav_data())
14.2. Text Preprocessing¶
check to see if a row only contains whitespace
def check_blanks(data_str):
is_blank = str(data_str.isspace())
return is_blank
Determine whether the language of the text content is english or not: Use langid module to classify the language to make sure we are applying the correct cleanup actions for English langid
def check_lang(data_str):
predict_lang = langid.classify(data_str)
if predict_lang[1] >= .9:
language = predict_lang[0]
else:
language = 'NA'
return language
Remove features
def remove_features(data_str):
# compile regex
url_re = re.compile('https?://(www.)?\w+\.\w+(/\w+)*/?')
punc_re = re.compile('[%s]' % re.escape(string.punctuation))
num_re = re.compile('(\\d+)')
mention_re = re.compile('@(\w+)')
alpha_num_re = re.compile("^[a-z0-9_.]+$")
# convert to lowercase
data_str = data_str.lower()
# remove hyperlinks
data_str = url_re.sub(' ', data_str)
# remove @mentions
data_str = mention_re.sub(' ', data_str)
# remove puncuation
data_str = punc_re.sub(' ', data_str)
# remove numeric 'words'
data_str = num_re.sub(' ', data_str)
# remove non a-z 0-9 characters and words shorter than 3 characters
list_pos = 0
cleaned_str = ''
for word in data_str.split():
if list_pos == 0:
if alpha_num_re.match(word) and len(word) > 2:
cleaned_str = word
else:
cleaned_str = ' '
else:
if alpha_num_re.match(word) and len(word) > 2:
cleaned_str = cleaned_str + ' ' + word
else:
cleaned_str += ' '
list_pos += 1
return cleaned_str
removes stop words
def remove_stops(data_str):
# expects a string
stops = set(stopwords.words("english"))
list_pos = 0
cleaned_str = ''
text = data_str.split()
for word in text:
if word not in stops:
# rebuild cleaned_str
if list_pos == 0:
cleaned_str = word
else:
cleaned_str = cleaned_str + ' ' + word
list_pos += 1
return cleaned_str
tagging text
def tag_and_remove(data_str):
cleaned_str = ' '
# noun tags
nn_tags = ['NN', 'NNP', 'NNP', 'NNPS', 'NNS']
# adjectives
jj_tags = ['JJ', 'JJR', 'JJS']
# verbs
vb_tags = ['VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ']
nltk_tags = nn_tags + jj_tags + vb_tags
# break string into 'words'
text = data_str.split()
# tag the text and keep only those with the right tags
tagged_text = pos_tag(text)
for tagged_word in tagged_text:
if tagged_word[1] in nltk_tags:
cleaned_str += tagged_word[0] + ' '
return cleaned_str
lemmatization
def lemmatize(data_str):
# expects a string
list_pos = 0
cleaned_str = ''
lmtzr = WordNetLemmatizer()
text = data_str.split()
tagged_words = pos_tag(text)
for word in tagged_words:
if 'v' in word[1].lower():
lemma = lmtzr.lemmatize(word[0], pos='v')
else:
lemma = lmtzr.lemmatize(word[0], pos='n')
if list_pos == 0:
cleaned_str = lemma
else:
cleaned_str = cleaned_str + ' ' + lemma
list_pos += 1
return cleaned_str
define the preprocessing function in PySpark
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
import preproc as pp
check_lang_udf = udf(pp.check_lang, StringType())
remove_stops_udf = udf(pp.remove_stops, StringType())
remove_features_udf = udf(pp.remove_features, StringType())
tag_and_remove_udf = udf(pp.tag_and_remove, StringType())
lemmatize_udf = udf(pp.lemmatize, StringType())
check_blanks_udf = udf(pp.check_blanks, StringType())
14.3. Text Classification¶
Theoretically speaking, you may apply any classification algorithms to do classification. I will only present Naive Bayes method is the following.
14.3.1. Introduction¶
14.3.2. Demo¶
create spark contexts
import pyspark
from pyspark.sql import SQLContext
# create spark contexts
sc = pyspark.SparkContext()
sqlContext = SQLContext(sc)
load dataset
# Load a text file and convert each line to a Row.
data_rdd = sc.textFile("../data/raw_data.txt")
parts_rdd = data_rdd.map(lambda l: l.split("\t"))
# Filter bad rows out
garantee_col_rdd = parts_rdd.filter(lambda l: len(l) == 3)
typed_rdd = garantee_col_rdd.map(lambda p: (p[0], p[1], float(p[2])))
#Create DataFrame
data_df = sqlContext.createDataFrame(typed_rdd, ["text", "id", "label"])
# get the raw columns
raw_cols = data_df.columns
#data_df.show()
data_df.printSchema()
root
|-- text: string (nullable = true)
|-- id: string (nullable = true)
|-- label: double (nullable = true)
+--------------------+------------------+-----+
| text| id|label|
+--------------------+------------------+-----+
|Fresh install of ...| 1018769417| 1.0|
|Well. Now I know ...| 10284216536| 1.0|
|"Literally six we...| 10298589026| 1.0|
|Mitsubishi i MiEV...|109017669432377344| 1.0|
+--------------------+------------------+-----+
only showing top 4 rows
setup pyspark udf function
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
import preproc as pp
# Register all the functions in Preproc with Spark Context
check_lang_udf = udf(pp.check_lang, StringType())
remove_stops_udf = udf(pp.remove_stops, StringType())
remove_features_udf = udf(pp.remove_features, StringType())
tag_and_remove_udf = udf(pp.tag_and_remove, StringType())
lemmatize_udf = udf(pp.lemmatize, StringType())
check_blanks_udf = udf(pp.check_blanks, StringType())
language identification
lang_df = data_df.withColumn("lang", check_lang_udf(data_df["text"]))
en_df = lang_df.filter(lang_df["lang"] == "en")
en_df.show(4)
+--------------------+------------------+-----+----+
| text| id|label|lang|
+--------------------+------------------+-----+----+
|RT @goeentertain:...|665305154954989568| 1.0| en|
|Teforia Uses Mach...|660668007975268352| 1.0| en|
| Apple TV or Roku?| 25842461136| 1.0| en|
|Finished http://t...| 9412369614| 1.0| en|
+--------------------+------------------+-----+----+
only showing top 4 rows
remove stop words
rm_stops_df = en_df.select(raw_cols)\
.withColumn("stop_text", remove_stops_udf(en_df["text"]))
rm_stops_df.show(4)
+--------------------+------------------+-----+--------------------+
| text| id|label| stop_text|
+--------------------+------------------+-----+--------------------+
|RT @goeentertain:...|665305154954989568| 1.0|RT @goeentertain:...|
|Teforia Uses Mach...|660668007975268352| 1.0|Teforia Uses Mach...|
| Apple TV or Roku?| 25842461136| 1.0| Apple TV Roku?|
|Finished http://t...| 9412369614| 1.0|Finished http://t...|
+--------------------+------------------+-----+--------------------+
only showing top 4 rows
remove irrelevant features
rm_features_df = rm_stops_df.select(raw_cols+["stop_text"])\
.withColumn("feat_text", \
remove_features_udf(rm_stops_df["stop_text"]))
rm_features_df.show(4)
+--------------------+------------------+-----+--------------------+--------------------+
| text| id|label| stop_text| feat_text|
+--------------------+------------------+-----+--------------------+--------------------+
|RT @goeentertain:...|665305154954989568| 1.0|RT @goeentertain:...| future blase ...|
|Teforia Uses Mach...|660668007975268352| 1.0|Teforia Uses Mach...|teforia uses mach...|
| Apple TV or Roku?| 25842461136| 1.0| Apple TV Roku?| apple roku|
|Finished http://t...| 9412369614| 1.0|Finished http://t...| finished|
+--------------------+------------------+-----+--------------------+--------------------+
only showing top 4 rows
tag the words
tagged_df = rm_features_df.select(raw_cols+["feat_text"]) \
.withColumn("tagged_text", \
tag_and_remove_udf(rm_features_df.feat_text))
tagged_df.show(4)
+--------------------+------------------+-----+--------------------+--------------------+
| text| id|label| feat_text| tagged_text|
+--------------------+------------------+-----+--------------------+--------------------+
|RT @goeentertain:...|665305154954989568| 1.0| future blase ...| future blase vic...|
|Teforia Uses Mach...|660668007975268352| 1.0|teforia uses mach...| teforia uses mac...|
| Apple TV or Roku?| 25842461136| 1.0| apple roku| apple roku |
|Finished http://t...| 9412369614| 1.0| finished| finished |
+--------------------+------------------+-----+--------------------+--------------------+
only showing top 4 rows
lemmatization of words
lemm_df = tagged_df.select(raw_cols+["tagged_text"]) \
.withColumn("lemm_text", lemmatize_udf(tagged_df["tagged_text"]))
lemm_df.show(4)
+--------------------+------------------+-----+--------------------+--------------------+
| text| id|label| tagged_text| lemm_text|
+--------------------+------------------+-----+--------------------+--------------------+
|RT @goeentertain:...|665305154954989568| 1.0| future blase vic...|future blase vice...|
|Teforia Uses Mach...|660668007975268352| 1.0| teforia uses mac...|teforia use machi...|
| Apple TV or Roku?| 25842461136| 1.0| apple roku | apple roku|
|Finished http://t...| 9412369614| 1.0| finished | finish|
+--------------------+------------------+-----+--------------------+--------------------+
only showing top 4 rows
remove blank rows and drop duplicates
check_blanks_df = lemm_df.select(raw_cols+["lemm_text"])\
.withColumn("is_blank", check_blanks_udf(lemm_df["lemm_text"]))
# remove blanks
no_blanks_df = check_blanks_df.filter(check_blanks_df["is_blank"] == "False")
# drop duplicates
dedup_df = no_blanks_df.dropDuplicates(['text', 'label'])
dedup_df.show(4)
+--------------------+------------------+-----+--------------------+--------+
| text| id|label| lemm_text|is_blank|
+--------------------+------------------+-----+--------------------+--------+
|RT @goeentertain:...|665305154954989568| 1.0|future blase vice...| False|
|Teforia Uses Mach...|660668007975268352| 1.0|teforia use machi...| False|
| Apple TV or Roku?| 25842461136| 1.0| apple roku| False|
|Finished http://t...| 9412369614| 1.0| finish| False|
+--------------------+------------------+-----+--------------------+--------+
only showing top 4 rows
add unieuq ID
from pyspark.sql.functions import monotonically_increasing_id
# Create Unique ID
dedup_df = dedup_df.withColumn("uid", monotonically_increasing_id())
dedup_df.show(4)
+--------------------+------------------+-----+--------------------+--------+------------+
| text| id|label| lemm_text|is_blank| uid|
+--------------------+------------------+-----+--------------------+--------+------------+
| dragon| 1546813742| 1.0| dragon| False| 85899345920|
| hurt much| 1558492525| 1.0| hurt much| False|111669149696|
|seth blog word se...|383221484023709697| 1.0|seth blog word se...| False|128849018880|
|teforia use machi...|660668007975268352| 1.0|teforia use machi...| False|137438953472|
+--------------------+------------------+-----+--------------------+--------+------------+
only showing top 4 rows
create final dataset
data = dedup_df.select('uid','id', 'text','label')
data.show(4)
+------------+------------------+--------------------+-----+
| uid| id| text|label|
+------------+------------------+--------------------+-----+
| 85899345920| 1546813742| dragon| 1.0|
|111669149696| 1558492525| hurt much| 1.0|
|128849018880|383221484023709697|seth blog word se...| 1.0|
|137438953472|660668007975268352|teforia use machi...| 1.0|
+------------+------------------+--------------------+-----+
only showing top 4 rows
Create taining and test sets
# Split the data into training and test sets (40% held out for testing)
(trainingData, testData) = data.randomSplit([0.6, 0.4])
NaiveBayes Pipeline
from pyspark.ml.feature import HashingTF, IDF, Tokenizer
from pyspark.ml import Pipeline
from pyspark.ml.classification import NaiveBayes, RandomForestClassifier
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml.tuning import ParamGridBuilder
from pyspark.ml.tuning import CrossValidator
from pyspark.ml.feature import IndexToString, StringIndexer, VectorIndexer
from pyspark.ml.feature import CountVectorizer
# Configure an ML pipeline, which consists of tree stages: tokenizer, hashingTF, and nb.
tokenizer = Tokenizer(inputCol="text", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="rawFeatures")
# vectorizer = CountVectorizer(inputCol= "words", outputCol="rawFeatures")
idf = IDF(minDocFreq=3, inputCol="rawFeatures", outputCol="features")
# Naive Bayes model
nb = NaiveBayes()
# Pipeline Architecture
pipeline = Pipeline(stages=[tokenizer, hashingTF, idf, nb])
# Train model. This also runs the indexers.
model = pipeline.fit(trainingData)
Make predictions
predictions = model.transform(testData)
# Select example rows to display.
predictions.select("text", "label", "prediction").show(5,False)
+-----------------------------------------------+-----+----------+
|text |label|prediction|
+-----------------------------------------------+-----+----------+
|finish |1.0 |1.0 |
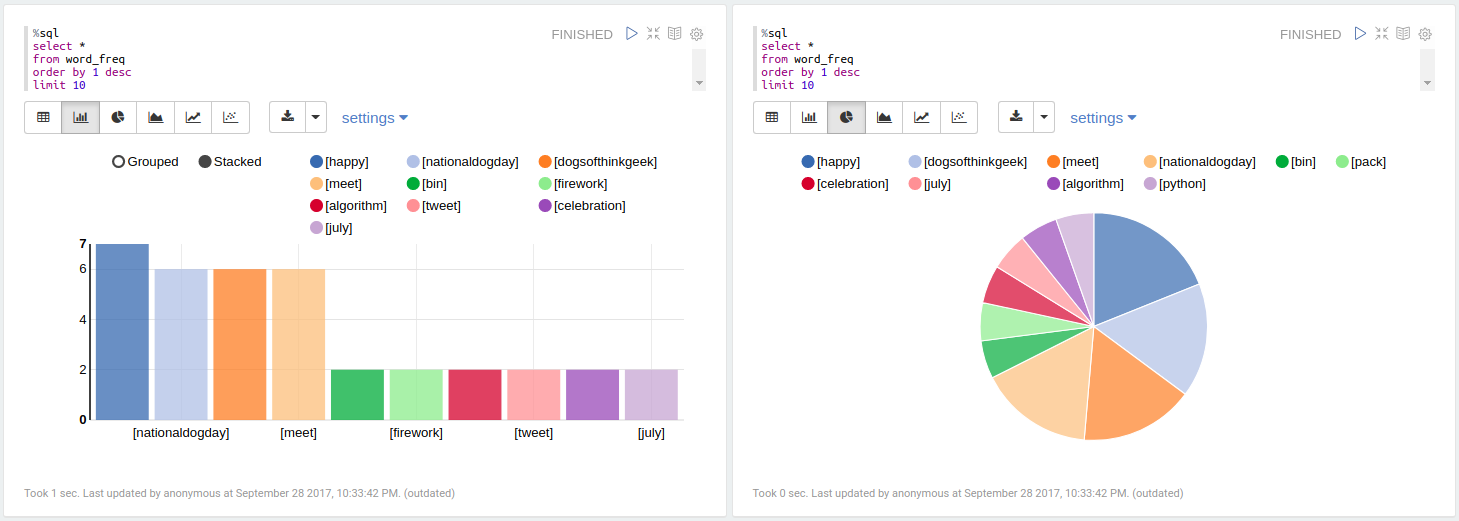
|meet rolo dogsofthinkgeek happy nationaldogday |1.0 |1.0 |
|pumpkin family |1.0 |1.0 |
|meet jet dogsofthinkgeek happy nationaldogday |1.0 |1.0 |
|meet vixie dogsofthinkgeek happy nationaldogday|1.0 |1.0 |
+-----------------------------------------------+-----+----------+
only showing top 5 rows
evaluation
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
evaluator = MulticlassClassificationEvaluator(predictionCol="prediction")
evaluator.evaluate(predictions)
0.912655971479501
14.4. Sentiment analysis¶
14.4.1. Introduction¶
Sentiment analysis (sometimes known as opinion mining or emotion AI) refers to the use of natural language processing, text analysis, computational linguistics, and biometrics to systematically identify, extract, quantify, and study affective states and subjective information. Sentiment analysis is widely applied to voice of the customer materials such as reviews and survey responses, online and social media, and healthcare materials for applications that range from marketing to customer service to clinical medicine.
Generally speaking, sentiment analysis aims to determine the attitude of a speaker, writer, or other subject with respect to some topic or the overall contextual polarity or emotional reaction to a document, interaction, or event. The attitude may be a judgment or evaluation (see appraisal theory), affective state (that is to say, the emotional state of the author or speaker), or the intended emotional communication (that is to say, the emotional effect intended by the author or interlocutor).
Sentiment analysis in business, also known as opinion mining is a process of identifying and cataloging a piece of text according to the tone conveyed by it. It has broad application:
Sentiment Analysis in Business Intelligence Build up
Sentiment Analysis in Business for Competitive Advantage
Enhancing the Customer Experience through Sentiment Analysis in Business

{kind=link}
{kind=link}
14.4.3. Demo¶
Set up spark context and SparkSession
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark Sentiment Analysis example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
Load dataset
df = spark.read.format('com.databricks.spark.csv').\
options(header='true', \
inferschema='true').\
load("../data/newtwitter.csv",header=True);
+--------------------+----------+-------+
| text| id|pubdate|
+--------------------+----------+-------+
|10 Things Missing...|2602860537| 18536|
|RT @_NATURALBWINN...|2602850443| 18536|
|RT @HBO24 yo the ...|2602761852| 18535|
|Aaaaaaaand I have...|2602738438| 18535|
|can I please have...|2602684185| 18535|
+--------------------+----------+-------+
only showing top 5 rows
Text Preprocessing
remove non ASCII characters
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
from nltk.stem.wordnet import WordNetLemmatizer
from nltk.corpus import stopwords
from nltk import pos_tag
import string
import re
# remove non ASCII characters
def strip_non_ascii(data_str):
''' Returns the string without non ASCII characters'''
stripped = (c for c in data_str if 0 < ord(c) < 127)
return ''.join(stripped)
# setup pyspark udf function
strip_non_ascii_udf = udf(strip_non_ascii, StringType())
check:
df = df.withColumn('text_non_asci',strip_non_ascii_udf(df['text']))
df.show(5,True)
ouput:
+--------------------+----------+-------+--------------------+
| text| id|pubdate| text_non_asci|
+--------------------+----------+-------+--------------------+
|10 Things Missing...|2602860537| 18536|10 Things Missing...|
|RT @_NATURALBWINN...|2602850443| 18536|RT @_NATURALBWINN...|
|RT @HBO24 yo the ...|2602761852| 18535|RT @HBO24 yo the ...|
|Aaaaaaaand I have...|2602738438| 18535|Aaaaaaaand I have...|
|can I please have...|2602684185| 18535|can I please have...|
+--------------------+----------+-------+--------------------+
only showing top 5 rows
fixed abbreviation
# fixed abbreviation
def fix_abbreviation(data_str):
data_str = data_str.lower()
data_str = re.sub(r'\bthats\b', 'that is', data_str)
data_str = re.sub(r'\bive\b', 'i have', data_str)
data_str = re.sub(r'\bim\b', 'i am', data_str)
data_str = re.sub(r'\bya\b', 'yeah', data_str)
data_str = re.sub(r'\bcant\b', 'can not', data_str)
data_str = re.sub(r'\bdont\b', 'do not', data_str)
data_str = re.sub(r'\bwont\b', 'will not', data_str)
data_str = re.sub(r'\bid\b', 'i would', data_str)
data_str = re.sub(r'wtf', 'what the fuck', data_str)
data_str = re.sub(r'\bwth\b', 'what the hell', data_str)
data_str = re.sub(r'\br\b', 'are', data_str)
data_str = re.sub(r'\bu\b', 'you', data_str)
data_str = re.sub(r'\bk\b', 'OK', data_str)
data_str = re.sub(r'\bsux\b', 'sucks', data_str)
data_str = re.sub(r'\bno+\b', 'no', data_str)
data_str = re.sub(r'\bcoo+\b', 'cool', data_str)
data_str = re.sub(r'rt\b', '', data_str)
data_str = data_str.strip()
return data_str
fix_abbreviation_udf = udf(fix_abbreviation, StringType())
- check:
df = df.withColumn('fixed_abbrev',fix_abbreviation_udf(df['text_non_asci'])) df.show(5,True)
ouput:
+--------------------+----------+-------+--------------------+--------------------+
| text| id|pubdate| text_non_asci| fixed_abbrev|
+--------------------+----------+-------+--------------------+--------------------+
|10 Things Missing...|2602860537| 18536|10 Things Missing...|10 things missing...|
|RT @_NATURALBWINN...|2602850443| 18536|RT @_NATURALBWINN...|@_naturalbwinner ...|
|RT @HBO24 yo the ...|2602761852| 18535|RT @HBO24 yo the ...|@hbo24 yo the #ne...|
|Aaaaaaaand I have...|2602738438| 18535|Aaaaaaaand I have...|aaaaaaaand i have...|
|can I please have...|2602684185| 18535|can I please have...|can i please have...|
+--------------------+----------+-------+--------------------+--------------------+
only showing top 5 rows
remove irrelevant features
def remove_features(data_str):
# compile regex
url_re = re.compile('https?://(www.)?\w+\.\w+(/\w+)*/?')
punc_re = re.compile('[%s]' % re.escape(string.punctuation))
num_re = re.compile('(\\d+)')
mention_re = re.compile('@(\w+)')
alpha_num_re = re.compile("^[a-z0-9_.]+$")
# convert to lowercase
data_str = data_str.lower()
# remove hyperlinks
data_str = url_re.sub(' ', data_str)
# remove @mentions
data_str = mention_re.sub(' ', data_str)
# remove puncuation
data_str = punc_re.sub(' ', data_str)
# remove numeric 'words'
data_str = num_re.sub(' ', data_str)
# remove non a-z 0-9 characters and words shorter than 1 characters
list_pos = 0
cleaned_str = ''
for word in data_str.split():
if list_pos == 0:
if alpha_num_re.match(word) and len(word) > 1:
cleaned_str = word
else:
cleaned_str = ' '
else:
if alpha_num_re.match(word) and len(word) > 1:
cleaned_str = cleaned_str + ' ' + word
else:
cleaned_str += ' '
list_pos += 1
# remove unwanted space, *.split() will automatically split on
# whitespace and discard duplicates, the " ".join() joins the
# resulting list into one string.
return " ".join(cleaned_str.split())
# setup pyspark udf function
remove_features_udf = udf(remove_features, StringType())
- check:
df = df.withColumn('removed',remove_features_udf(df['fixed_abbrev'])) df.show(5,True)
ouput:
+--------------------+----------+-------+--------------------+--------------------+--------------------+
| text| id|pubdate| text_non_asci| fixed_abbrev| removed|
+--------------------+----------+-------+--------------------+--------------------+--------------------+
|10 Things Missing...|2602860537| 18536|10 Things Missing...|10 things missing...|things missing in...|
|RT @_NATURALBWINN...|2602850443| 18536|RT @_NATURALBWINN...|@_naturalbwinner ...|oh and do not lik...|
|RT @HBO24 yo the ...|2602761852| 18535|RT @HBO24 yo the ...|@hbo24 yo the #ne...|yo the newtwitter...|
|Aaaaaaaand I have...|2602738438| 18535|Aaaaaaaand I have...|aaaaaaaand i have...|aaaaaaaand have t...|
|can I please have...|2602684185| 18535|can I please have...|can i please have...|can please have t...|
+--------------------+----------+-------+--------------------+--------------------+--------------------+
only showing top 5 rows
Sentiment Analysis main function
from pyspark.sql.types import FloatType
from textblob import TextBlob
def sentiment_analysis(text):
return TextBlob(text).sentiment.polarity
sentiment_analysis_udf = udf(sentiment_analysis , FloatType())
df = df.withColumn("sentiment_score", sentiment_analysis_udf( df['removed'] ))
df.show(5,True)
Sentiment score
+--------------------+---------------+
| removed|sentiment_score|
+--------------------+---------------+
|things missing in...| -0.03181818|
|oh and do not lik...| -0.03181818|
|yo the newtwitter...| 0.3181818|
|aaaaaaaand have t...| 0.11818182|
|can please have t...| 0.13636364|
+--------------------+---------------+
only showing top 5 rows
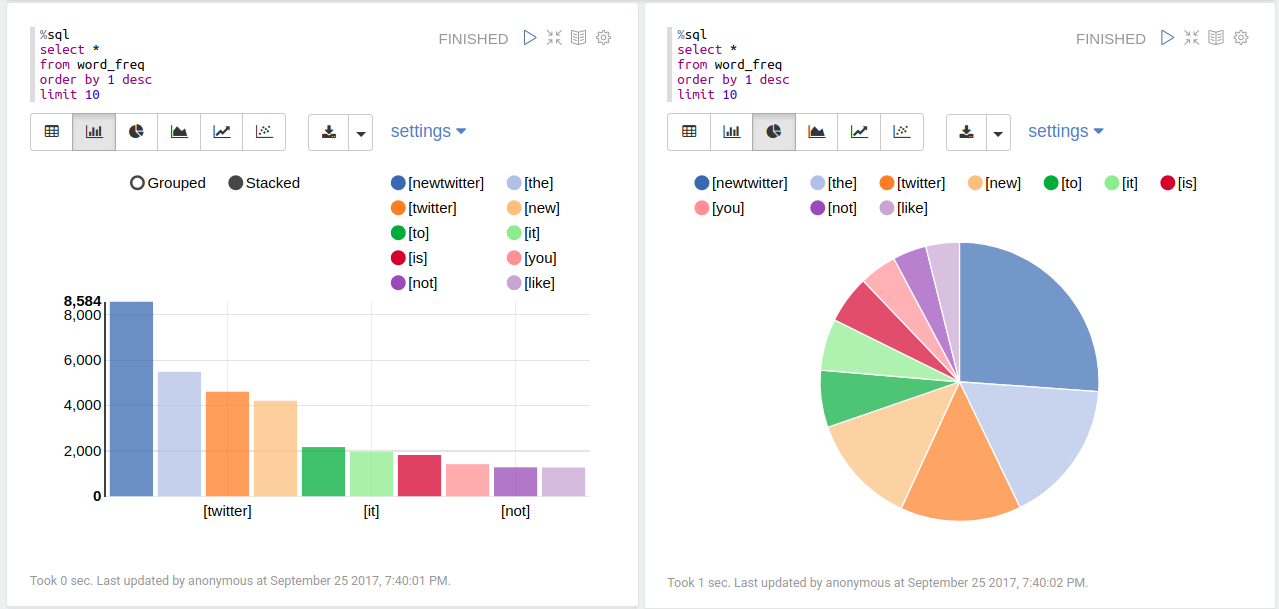
Words frequency
Sentiment Classification
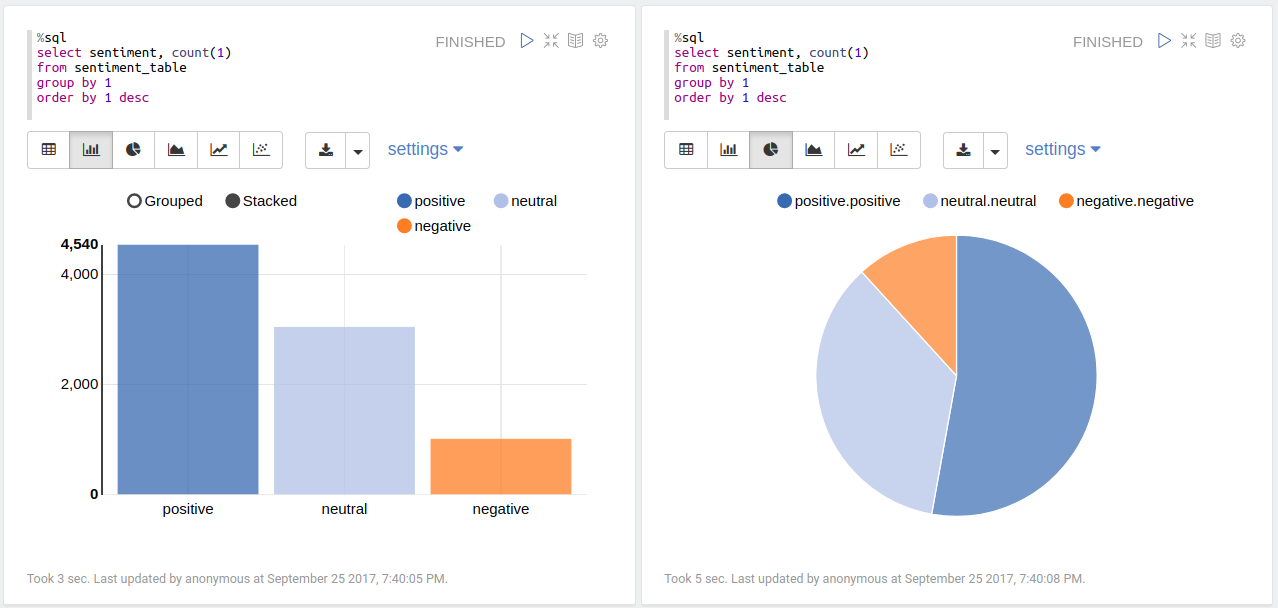
def condition(r): if (r >=0.1): label = "positive" elif(r <= -0.1): label = "negative" else: label = "neutral" return label sentiment_udf = udf(lambda x: condition(x), StringType())
Output
Sentiment Class
Top tweets from each sentiment class
+--------------------+---------------+---------+ | text|sentiment_score|sentiment| +--------------------+---------------+---------+ |and this #newtwit...| 1.0| positive| |"RT @SarahsJokes:...| 1.0| positive| |#newtwitter using...| 1.0| positive| |The #NewTwitter h...| 1.0| positive| |You can now undo ...| 1.0| positive| +--------------------+---------------+---------+ only showing top 5 rows+--------------------+---------------+---------+ | text|sentiment_score|sentiment| +--------------------+---------------+---------+ |Lists on #NewTwit...| -0.1| neutral| |Too bad most of m...| -0.1| neutral| |the #newtwitter i...| -0.1| neutral| |Looks like our re...| -0.1| neutral| |i switched to the...| -0.1| neutral| +--------------------+---------------+---------+ only showing top 5 rows+--------------------+---------------+---------+ | text|sentiment_score|sentiment| +--------------------+---------------+---------+ |oh. #newtwitter i...| -1.0| negative| |RT @chqwn: #NewTw...| -1.0| negative| |Copy that - its W...| -1.0| negative| |RT @chqwn: #NewTw...| -1.0| negative| |#NewTwitter has t...| -1.0| negative| +--------------------+---------------+---------+ only showing top 5 rows
14.5. N-grams and Correlations¶
14.6. Topic Model: Latent Dirichlet Allocation¶
14.6.1. Introduction¶
In text mining, a topic model is a unsupervised model for discovering the abstract “topics” that occur in a collection of documents.
Latent Dirichlet Allocation (LDA) is a mathematical method for estimating both of these at the same time: finding the mixture of words that is associated with each topic, while also determining the mixture of topics that describes each document.
14.6.2. Demo¶
Load data
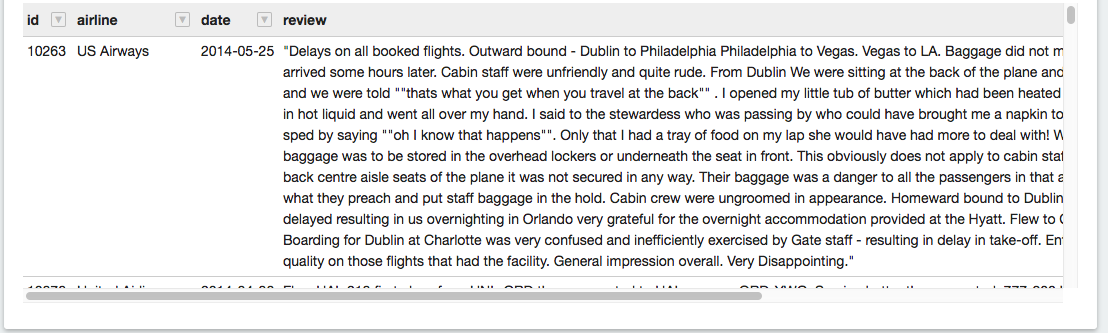
rawdata = spark.read.load("../data/airlines.csv", format="csv", header=True) rawdata.show(5)+-----+---------------+---------+--------+------+--------+-----+-----------+--------------------+ | id| airline| date|location|rating| cabin|value|recommended| review| +-----+---------------+---------+--------+------+--------+-----+-----------+--------------------+ |10001|Delta Air Lines|21-Jun-14|Thailand| 7| Economy| 4| YES|Flew Mar 30 NRT t...| |10002|Delta Air Lines|19-Jun-14| USA| 0| Economy| 2| NO|Flight 2463 leavi...| |10003|Delta Air Lines|18-Jun-14| USA| 0| Economy| 1| NO|Delta Website fro...| |10004|Delta Air Lines|17-Jun-14| USA| 9|Business| 4| YES|"I just returned ...| |10005|Delta Air Lines|17-Jun-14| Ecuador| 7| Economy| 3| YES|"Round-trip fligh...| +-----+---------------+---------+--------+------+--------+-----+-----------+--------------------+ only showing top 5 rows
Text preprocessing
I will use the following raw column names to keep my table concise:
raw_cols = rawdata.columns raw_cols['id', 'airline', 'date', 'location', 'rating', 'cabin', 'value', 'recommended', 'review']rawdata = rawdata.dropDuplicates(['review'])from pyspark.sql.functions import udf, col from pyspark.sql.types import StringType, DoubleType, DateType from nltk.stem.wordnet import WordNetLemmatizer from nltk.corpus import stopwords from nltk import pos_tag import langid import string import re
remove non ASCII characters
# remove non ASCII characters def strip_non_ascii(data_str): ''' Returns the string without non ASCII characters''' stripped = (c for c in data_str if 0 < ord(c) < 127) return ''.join(stripped)
check it blank line or not
# check to see if a row only contains whitespace def check_blanks(data_str): is_blank = str(data_str.isspace()) return is_blank
check the language (a little bit slow, I skited this step)
# check the language (only apply to english) def check_lang(data_str): from langid.langid import LanguageIdentifier, model identifier = LanguageIdentifier.from_modelstring(model, norm_probs=True) predict_lang = identifier.classify(data_str) if predict_lang[1] >= .9: language = predict_lang[0] else: language = predict_lang[0] return language
fixed abbreviation
# fixed abbreviation def fix_abbreviation(data_str): data_str = data_str.lower() data_str = re.sub(r'\bthats\b', 'that is', data_str) data_str = re.sub(r'\bive\b', 'i have', data_str) data_str = re.sub(r'\bim\b', 'i am', data_str) data_str = re.sub(r'\bya\b', 'yeah', data_str) data_str = re.sub(r'\bcant\b', 'can not', data_str) data_str = re.sub(r'\bdont\b', 'do not', data_str) data_str = re.sub(r'\bwont\b', 'will not', data_str) data_str = re.sub(r'\bid\b', 'i would', data_str) data_str = re.sub(r'wtf', 'what the fuck', data_str) data_str = re.sub(r'\bwth\b', 'what the hell', data_str) data_str = re.sub(r'\br\b', 'are', data_str) data_str = re.sub(r'\bu\b', 'you', data_str) data_str = re.sub(r'\bk\b', 'OK', data_str) data_str = re.sub(r'\bsux\b', 'sucks', data_str) data_str = re.sub(r'\bno+\b', 'no', data_str) data_str = re.sub(r'\bcoo+\b', 'cool', data_str) data_str = re.sub(r'rt\b', '', data_str) data_str = data_str.strip() return data_str
remove irrelevant features
# remove irrelevant features def remove_features(data_str): # compile regex url_re = re.compile('https?://(www.)?\w+\.\w+(/\w+)*/?') punc_re = re.compile('[%s]' % re.escape(string.punctuation)) num_re = re.compile('(\\d+)') mention_re = re.compile('@(\w+)') alpha_num_re = re.compile("^[a-z0-9_.]+$") # convert to lowercase data_str = data_str.lower() # remove hyperlinks data_str = url_re.sub(' ', data_str) # remove @mentions data_str = mention_re.sub(' ', data_str) # remove puncuation data_str = punc_re.sub(' ', data_str) # remove numeric 'words' data_str = num_re.sub(' ', data_str) # remove non a-z 0-9 characters and words shorter than 1 characters list_pos = 0 cleaned_str = '' for word in data_str.split(): if list_pos == 0: if alpha_num_re.match(word) and len(word) > 1: cleaned_str = word else: cleaned_str = ' ' else: if alpha_num_re.match(word) and len(word) > 1: cleaned_str = cleaned_str + ' ' + word else: cleaned_str += ' ' list_pos += 1 # remove unwanted space, *.split() will automatically split on # whitespace and discard duplicates, the " ".join() joins the # resulting list into one string. return " ".join(cleaned_str.split())
removes stop words
# removes stop words def remove_stops(data_str): # expects a string stops = set(stopwords.words("english")) list_pos = 0 cleaned_str = '' text = data_str.split() for word in text: if word not in stops: # rebuild cleaned_str if list_pos == 0: cleaned_str = word else: cleaned_str = cleaned_str + ' ' + word list_pos += 1 return cleaned_str
Part-of-Speech Tagging
# Part-of-Speech Tagging def tag_and_remove(data_str): cleaned_str = ' ' # noun tags nn_tags = ['NN', 'NNP', 'NNP', 'NNPS', 'NNS'] # adjectives jj_tags = ['JJ', 'JJR', 'JJS'] # verbs vb_tags = ['VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ'] nltk_tags = nn_tags + jj_tags + vb_tags # break string into 'words' text = data_str.split() # tag the text and keep only those with the right tags tagged_text = pos_tag(text) for tagged_word in tagged_text: if tagged_word[1] in nltk_tags: cleaned_str += tagged_word[0] + ' ' return cleaned_str
lemmatization
# lemmatization def lemmatize(data_str): # expects a string list_pos = 0 cleaned_str = '' lmtzr = WordNetLemmatizer() text = data_str.split() tagged_words = pos_tag(text) for word in tagged_words: if 'v' in word[1].lower(): lemma = lmtzr.lemmatize(word[0], pos='v') else: lemma = lmtzr.lemmatize(word[0], pos='n') if list_pos == 0: cleaned_str = lemma else: cleaned_str = cleaned_str + ' ' + lemma list_pos += 1 return cleaned_str
setup pyspark udf function
# setup pyspark udf function strip_non_ascii_udf = udf(strip_non_ascii, StringType()) check_blanks_udf = udf(check_blanks, StringType()) check_lang_udf = udf(check_lang, StringType()) fix_abbreviation_udf = udf(fix_abbreviation, StringType()) remove_stops_udf = udf(remove_stops, StringType()) remove_features_udf = udf(remove_features, StringType()) tag_and_remove_udf = udf(tag_and_remove, StringType()) lemmatize_udf = udf(lemmatize, StringType())
Text processing
correct the data schema
rawdata = rawdata.withColumn('rating', rawdata.rating.cast('float'))rawdata.printSchema()root |-- id: string (nullable = true) |-- airline: string (nullable = true) |-- date: string (nullable = true) |-- location: string (nullable = true) |-- rating: float (nullable = true) |-- cabin: string (nullable = true) |-- value: string (nullable = true) |-- recommended: string (nullable = true) |-- review: string (nullable = true)from datetime import datetime from pyspark.sql.functions import col # https://docs.python.org/2/library/datetime.html#strftime-and-strptime-behavior # 21-Jun-14 <----> %d-%b-%y to_date = udf (lambda x: datetime.strptime(x, '%d-%b-%y'), DateType()) rawdata = rawdata.withColumn('date', to_date(col('date')))rawdata.printSchema()root |-- id: string (nullable = true) |-- airline: string (nullable = true) |-- date: date (nullable = true) |-- location: string (nullable = true) |-- rating: float (nullable = true) |-- cabin: string (nullable = true) |-- value: string (nullable = true) |-- recommended: string (nullable = true) |-- review: string (nullable = true)rawdata.show(5)+-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+ | id| airline| date|location|rating| cabin|value|recommended| review| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+ |10551|Southwest Airlines|2013-11-06| USA| 1.0|Business| 2| NO|Flight 3246 from ...| |10298| US Airways|2014-03-31| UK| 1.0|Business| 0| NO|Flight from Manch...| |10564|Southwest Airlines|2013-09-06| USA| 10.0| Economy| 5| YES|I'm Executive Pla...| |10134| Delta Air Lines|2013-12-10| USA| 8.0| Economy| 4| YES|MSP-JFK-MXP and r...| |10912| United Airlines|2014-04-07| USA| 3.0| Economy| 1| NO|Worst airline I h...| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+ only showing top 5 rowsrawdata = rawdata.withColumn('non_asci', strip_non_ascii_udf(rawdata['review'])) +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+ | id| airline| date|location|rating| cabin|value|recommended| review| non_asci| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+ |10551|Southwest Airlines|2013-11-06| USA| 1.0|Business| 2| NO|Flight 3246 from ...|Flight 3246 from ...| |10298| US Airways|2014-03-31| UK| 1.0|Business| 0| NO|Flight from Manch...|Flight from Manch...| |10564|Southwest Airlines|2013-09-06| USA| 10.0| Economy| 5| YES|I'm Executive Pla...|I'm Executive Pla...| |10134| Delta Air Lines|2013-12-10| USA| 8.0| Economy| 4| YES|MSP-JFK-MXP and r...|MSP-JFK-MXP and r...| |10912| United Airlines|2014-04-07| USA| 3.0| Economy| 1| NO|Worst airline I h...|Worst airline I h...| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+ only showing top 5 rowsrawdata = rawdata.select(raw_cols+['non_asci'])\ .withColumn('fixed_abbrev',fix_abbreviation_udf(rawdata['non_asci'])) +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ | id| airline| date|location|rating| cabin|value|recommended| review| non_asci| fixed_abbrev| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ |10551|Southwest Airlines|2013-11-06| USA| 1.0|Business| 2| NO|Flight 3246 from ...|Flight 3246 from ...|flight 3246 from ...| |10298| US Airways|2014-03-31| UK| 1.0|Business| 0| NO|Flight from Manch...|Flight from Manch...|flight from manch...| |10564|Southwest Airlines|2013-09-06| USA| 10.0| Economy| 5| YES|I'm Executive Pla...|I'm Executive Pla...|i'm executive pla...| |10134| Delta Air Lines|2013-12-10| USA| 8.0| Economy| 4| YES|MSP-JFK-MXP and r...|MSP-JFK-MXP and r...|msp-jfk-mxp and r...| |10912| United Airlines|2014-04-07| USA| 3.0| Economy| 1| NO|Worst airline I h...|Worst airline I h...|worst airline i h...| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ only showing top 5 rowsrawdata = rawdata.select(raw_cols+['fixed_abbrev'])\ .withColumn('stop_text',remove_stops_udf(rawdata['fixed_abbrev'])) +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ | id| airline| date|location|rating| cabin|value|recommended| review| fixed_abbrev| stop_text| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ |10551|Southwest Airlines|2013-11-06| USA| 1.0|Business| 2| NO|Flight 3246 from ...|flight 3246 from ...|flight 3246 chica...| |10298| US Airways|2014-03-31| UK| 1.0|Business| 0| NO|Flight from Manch...|flight from manch...|flight manchester...| |10564|Southwest Airlines|2013-09-06| USA| 10.0| Economy| 5| YES|I'm Executive Pla...|i'm executive pla...|i'm executive pla...| |10134| Delta Air Lines|2013-12-10| USA| 8.0| Economy| 4| YES|MSP-JFK-MXP and r...|msp-jfk-mxp and r...|msp-jfk-mxp retur...| |10912| United Airlines|2014-04-07| USA| 3.0| Economy| 1| NO|Worst airline I h...|worst airline i h...|worst airline eve...| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ only showing top 5 rowsrawdata = rawdata.select(raw_cols+['stop_text'])\ .withColumn('feat_text',remove_features_udf(rawdata['stop_text'])) +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ | id| airline| date|location|rating| cabin|value|recommended| review| stop_text| feat_text| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ |10551|Southwest Airlines|2013-11-06| USA| 1.0|Business| 2| NO|Flight 3246 from ...|flight 3246 chica...|flight chicago mi...| |10298| US Airways|2014-03-31| UK| 1.0|Business| 0| NO|Flight from Manch...|flight manchester...|flight manchester...| |10564|Southwest Airlines|2013-09-06| USA| 10.0| Economy| 5| YES|I'm Executive Pla...|i'm executive pla...|executive platinu...| |10134| Delta Air Lines|2013-12-10| USA| 8.0| Economy| 4| YES|MSP-JFK-MXP and r...|msp-jfk-mxp retur...|msp jfk mxp retur...| |10912| United Airlines|2014-04-07| USA| 3.0| Economy| 1| NO|Worst airline I h...|worst airline eve...|worst airline eve...| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ only showing top 5 rowsrawdata = rawdata.select(raw_cols+['feat_text'])\ .withColumn('tagged_text',tag_and_remove_udf(rawdata['feat_text'])) +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ | id| airline| date|location|rating| cabin|value|recommended| review| feat_text| tagged_text| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ |10551|Southwest Airlines|2013-11-06| USA| 1.0|Business| 2| NO|Flight 3246 from ...|flight chicago mi...| flight chicago m...| |10298| US Airways|2014-03-31| UK| 1.0|Business| 0| NO|Flight from Manch...|flight manchester...| flight mancheste...| |10564|Southwest Airlines|2013-09-06| USA| 10.0| Economy| 5| YES|I'm Executive Pla...|executive platinu...| executive platin...| |10134| Delta Air Lines|2013-12-10| USA| 8.0| Economy| 4| YES|MSP-JFK-MXP and r...|msp jfk mxp retur...| msp jfk mxp retu...| |10912| United Airlines|2014-04-07| USA| 3.0| Economy| 1| NO|Worst airline I h...|worst airline eve...| worst airline ua...| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ only showing top 5 rowsrawdata = rawdata.select(raw_cols+['tagged_text']) \ .withColumn('lemm_text',lemmatize_udf(rawdata['tagged_text']) +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ | id| airline| date|location|rating| cabin|value|recommended| review| tagged_text| lemm_text| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ |10551|Southwest Airlines|2013-11-06| USA| 1.0|Business| 2| NO|Flight 3246 from ...| flight chicago m...|flight chicago mi...| |10298| US Airways|2014-03-31| UK| 1.0|Business| 0| NO|Flight from Manch...| flight mancheste...|flight manchester...| |10564|Southwest Airlines|2013-09-06| USA| 10.0| Economy| 5| YES|I'm Executive Pla...| executive platin...|executive platinu...| |10134| Delta Air Lines|2013-12-10| USA| 8.0| Economy| 4| YES|MSP-JFK-MXP and r...| msp jfk mxp retu...|msp jfk mxp retur...| |10912| United Airlines|2014-04-07| USA| 3.0| Economy| 1| NO|Worst airline I h...| worst airline ua...|worst airline ual...| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------------------+ only showing top 5 rowsrawdata = rawdata.select(raw_cols+['lemm_text']) \ .withColumn("is_blank", check_blanks_udf(rawdata["lemm_text"])) +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------+ | id| airline| date|location|rating| cabin|value|recommended| review| lemm_text|is_blank| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------+ |10551|Southwest Airlines|2013-11-06| USA| 1.0|Business| 2| NO|Flight 3246 from ...|flight chicago mi...| False| |10298| US Airways|2014-03-31| UK| 1.0|Business| 0| NO|Flight from Manch...|flight manchester...| False| |10564|Southwest Airlines|2013-09-06| USA| 10.0| Economy| 5| YES|I'm Executive Pla...|executive platinu...| False| |10134| Delta Air Lines|2013-12-10| USA| 8.0| Economy| 4| YES|MSP-JFK-MXP and r...|msp jfk mxp retur...| False| |10912| United Airlines|2014-04-07| USA| 3.0| Economy| 1| NO|Worst airline I h...|worst airline ual...| False| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------+ only showing top 5 rowsfrom pyspark.sql.functions import monotonically_increasing_id # Create Unique ID rawdata = rawdata.withColumn("uid", monotonically_increasing_id()) data = rawdata.filter(rawdata["is_blank"] == "False") +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------+---+ | id| airline| date|location|rating| cabin|value|recommended| review| lemm_text|is_blank|uid| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------+---+ |10551|Southwest Airlines|2013-11-06| USA| 1.0|Business| 2| NO|Flight 3246 from ...|flight chicago mi...| False| 0| |10298| US Airways|2014-03-31| UK| 1.0|Business| 0| NO|Flight from Manch...|flight manchester...| False| 1| |10564|Southwest Airlines|2013-09-06| USA| 10.0| Economy| 5| YES|I'm Executive Pla...|executive platinu...| False| 2| |10134| Delta Air Lines|2013-12-10| USA| 8.0| Economy| 4| YES|MSP-JFK-MXP and r...|msp jfk mxp retur...| False| 3| |10912| United Airlines|2014-04-07| USA| 3.0| Economy| 1| NO|Worst airline I h...|worst airline ual...| False| 4| +-----+------------------+----------+--------+------+--------+-----+-----------+--------------------+--------------------+--------+---+ only showing top 5 rows
# Pipeline for LDA model
from pyspark.ml.feature import HashingTF, IDF, Tokenizer from pyspark.ml import Pipeline from pyspark.ml.classification import NaiveBayes, RandomForestClassifier from pyspark.ml.clustering import LDA from pyspark.ml.classification import DecisionTreeClassifier from pyspark.ml.evaluation import MulticlassClassificationEvaluator from pyspark.ml.tuning import ParamGridBuilder from pyspark.ml.tuning import CrossValidator from pyspark.ml.feature import IndexToString, StringIndexer, VectorIndexer from pyspark.ml.feature import CountVectorizer # Configure an ML pipeline, which consists of tree stages: tokenizer, hashingTF, and nb. tokenizer = Tokenizer(inputCol="lemm_text", outputCol="words") #data = tokenizer.transform(data) vectorizer = CountVectorizer(inputCol= "words", outputCol="rawFeatures") idf = IDF(inputCol="rawFeatures", outputCol="features") #idfModel = idf.fit(data) lda = LDA(k=20, seed=1, optimizer="em") pipeline = Pipeline(stages=[tokenizer, vectorizer,idf, lda]) model = pipeline.fit(data)
Results presentation
Topics
+-----+--------------------+--------------------+ |topic| termIndices| termWeights| +-----+--------------------+--------------------+ | 0|[60, 7, 12, 483, ...|[0.01349507958269...| | 1|[363, 29, 187, 55...|[0.01247250144447...| | 2|[46, 107, 672, 27...|[0.01188684264641...| | 3|[76, 43, 285, 152...|[0.01132638300115...| | 4|[201, 13, 372, 69...|[0.01337529863256...| | 5|[122, 103, 181, 4...|[0.00930415977117...| | 6|[14, 270, 18, 74,...|[0.01253817708163...| | 7|[111, 36, 341, 10...|[0.01269584954257...| | 8|[477, 266, 297, 1...|[0.01017486869509...| | 9|[10, 73, 46, 1, 2...|[0.01050875237546...| | 10|[57, 29, 411, 10,...|[0.01777350667863...| | 11|[293, 119, 385, 4...|[0.01280305149305...| | 12|[116, 218, 256, 1...|[0.01570714218509...| | 13|[433, 171, 176, 3...|[0.00819684813575...| | 14|[74, 84, 45, 108,...|[0.01700630002172...| | 15|[669, 215, 14, 58...|[0.00779310974971...| | 16|[198, 21, 98, 164...|[0.01030577084202...| | 17|[96, 29, 569, 444...|[0.01297142577633...| | 18|[18, 60, 140, 64,...|[0.01306356985169...| | 19|[33, 178, 95, 2, ...|[0.00907425683229...| +-----+--------------------+--------------------+
Topic terms
from pyspark.sql.types import ArrayType, StringType def termsIdx2Term(vocabulary): def termsIdx2Term(termIndices): return [vocabulary[int(index)] for index in termIndices] return udf(termsIdx2Term, ArrayType(StringType())) vectorizerModel = model.stages[1] vocabList = vectorizerModel.vocabulary final = ldatopics.withColumn("Terms", termsIdx2Term(vocabList)("termIndices"))+-----+------------------------------------------------+-------------------------------------------------------------------------------------+ |topic|termIndices |Terms | +-----+------------------------------------------------+-------------------------------------------------------------------------------------+ |0 |[60, 7, 12, 483, 292, 326, 88, 4, 808, 32] |[pm, plane, board, kid, online, lga, schedule, get, memphis, arrive] | |1 |[363, 29, 187, 55, 48, 647, 30, 9, 204, 457] |[dublin, class, th, sit, entertainment, express, say, delay, dl, son] | |2 |[46, 107, 672, 274, 92, 539, 23, 27, 279, 8] |[economy, sfo, milwaukee, decent, comfortable, iad, return, united, average, airline]| |3 |[76, 43, 285, 152, 102, 34, 300, 113, 24, 31] |[didn, pay, lose, different, extra, bag, mile, baggage, leave, day] | |4 |[201, 13, 372, 692, 248, 62, 211, 187, 105, 110]|[houston, crew, heathrow, louisville, london, great, denver, th, land, jfk] | |5 |[122, 103, 181, 48, 434, 10, 121, 147, 934, 169]|[lhr, serve, screen, entertainment, ny, delta, excellent, atl, sin, newark] | |6 |[14, 270, 18, 74, 70, 37, 16, 450, 3, 20] |[check, employee, gate, line, change, wait, take, fll, time, tell] | |7 |[111, 36, 341, 10, 320, 528, 844, 19, 195, 524] |[atlanta, first, toilet, delta, washington, card, global, staff, route, amsterdam] | |8 |[477, 266, 297, 185, 1, 33, 22, 783, 17, 908] |[fuel, group, pas, boarding, seat, trip, minute, orleans, make, select] | |9 |[10, 73, 46, 1, 248, 302, 213, 659, 48, 228] |[delta, lax, economy, seat, london, detroit, comfo, weren, entertainment, wife] | |10 |[57, 29, 411, 10, 221, 121, 661, 19, 805, 733] |[business, class, fra, delta, lounge, excellent, syd, staff, nov, mexico] | |11 |[293, 119, 385, 481, 503, 69, 13, 87, 176, 545] |[march, ua, manchester, phx, envoy, drink, crew, american, aa, canada] | |12 |[116, 218, 256, 156, 639, 20, 365, 18, 22, 136] |[san, clt, francisco, second, text, tell, captain, gate, minute, available] | |13 |[433, 171, 176, 339, 429, 575, 10, 26, 474, 796]|[daughter, small, aa, ba, segment, proceed, delta, passenger, size, similar] | |14 |[74, 84, 45, 108, 342, 111, 315, 87, 52, 4] |[line, agent, next, hotel, standby, atlanta, dallas, american, book, get] | |15 |[669, 215, 14, 58, 561, 59, 125, 179, 93, 5] |[fit, carry, check, people, bathroom, ask, thing, row, don, fly] | |16 |[198, 21, 98, 164, 57, 141, 345, 62, 121, 174] |[ife, good, nice, much, business, lot, dfw, great, excellent, carrier] | |17 |[96, 29, 569, 444, 15, 568, 21, 103, 657, 505] |[phl, class, diego, lady, food, wheelchair, good, serve, miami, mia] | |18 |[18, 60, 140, 64, 47, 40, 31, 35, 2, 123] |[gate, pm, phoenix, connection, cancel, connect, day, airpo, hour, charlotte] | |19 |[33, 178, 95, 2, 9, 284, 42, 4, 89, 31] |[trip, counter, philadelphia, hour, delay, stay, way, get, southwest, day] | +-----+------------------------------------------------+-------------------------------------------------------------------------------------+
LDA results
+-----+------------------+----------+-----------+------+--------------------+--------------------+--------------------+ | id| airline| date| cabin|rating| words| features| topicDistribution| +-----+------------------+----------+-----------+------+--------------------+--------------------+--------------------+ |10551|Southwest Airlines|2013-11-06| Business| 1.0|[flight, chicago,...|(4695,[0,2,3,6,11...|[0.03640342580508...| |10298| US Airways|2014-03-31| Business| 1.0|[flight, manchest...|(4695,[0,1,2,6,7,...|[0.01381306271470...| |10564|Southwest Airlines|2013-09-06| Economy| 10.0|[executive, plati...|(4695,[0,1,6,7,11...|[0.05063554352934...| |10134| Delta Air Lines|2013-12-10| Economy| 8.0|[msp, jfk, mxp, r...|(4695,[0,1,3,10,1...|[0.01494708959842...| |10912| United Airlines|2014-04-07| Economy| 3.0|[worst, airline, ...|(4695,[0,1,7,8,13...|[0.04421751181232...| |10089| Delta Air Lines|2014-02-18| Economy| 2.0|[dl, mia, lax, im...|(4695,[2,4,5,7,8,...|[0.02158861273876...| |10385| US Airways|2013-10-21| Economy| 10.0|[flew, gla, phl, ...|(4695,[0,1,3,5,14...|[0.03343845991816...| |10249| US Airways|2014-06-17| Economy| 1.0|[friend, book, fl...|(4695,[0,2,3,4,5,...|[0.02362432562165...| |10289| US Airways|2014-04-12| Economy| 10.0|[flew, air, rome,...|(4695,[0,1,5,8,13...|[0.01664012816210...| |10654|Southwest Airlines|2012-07-10| Economy| 8.0|[lhr, jfk, think,...|(4695,[0,4,5,6,8,...|[0.01526072330297...| |10754| American Airlines|2014-05-04| Economy| 10.0|[san, diego, moli...|(4695,[0,2,8,15,2...|[0.03571177612496...| |10646|Southwest Airlines|2012-08-17| Economy| 7.0|[toledo, co, stop...|(4695,[0,2,3,4,7,...|[0.02394775146271...| |10097| Delta Air Lines|2014-02-03|First Class| 10.0|[honolulu, la, fi...|(4695,[0,4,6,7,13...|[0.02008375619661...| |10132| Delta Air Lines|2013-12-16| Economy| 7.0|[manchester, uk, ...|(4695,[0,1,2,3,5,...|[0.01463126146601...| |10560|Southwest Airlines|2013-09-20| Economy| 9.0|[first, time, sou...|(4695,[0,3,7,8,9,...|[0.04934836409896...| |10579|Southwest Airlines|2013-07-25| Economy| 0.0|[plane, land, pm,...|(4695,[2,3,4,5,7,...|[0.06106959241722...| |10425| US Airways|2013-08-06| Economy| 3.0|[airway, bad, pro...|(4695,[2,3,4,7,8,...|[0.01770471771322...| |10650|Southwest Airlines|2012-07-27| Economy| 9.0|[flew, jfk, lhr, ...|(4695,[0,1,6,13,1...|[0.02676226245086...| |10260| US Airways|2014-06-03| Economy| 1.0|[february, air, u...|(4695,[0,2,4,17,2...|[0.02887390875079...| |10202| Delta Air Lines|2013-09-14| Economy| 10.0|[aug, lhr, jfk, b...|(4695,[1,2,4,7,10...|[0.02377704988307...| +-----+------------------+----------+-----------+------+--------------------+--------------------+--------------------+ only showing top 20 rows
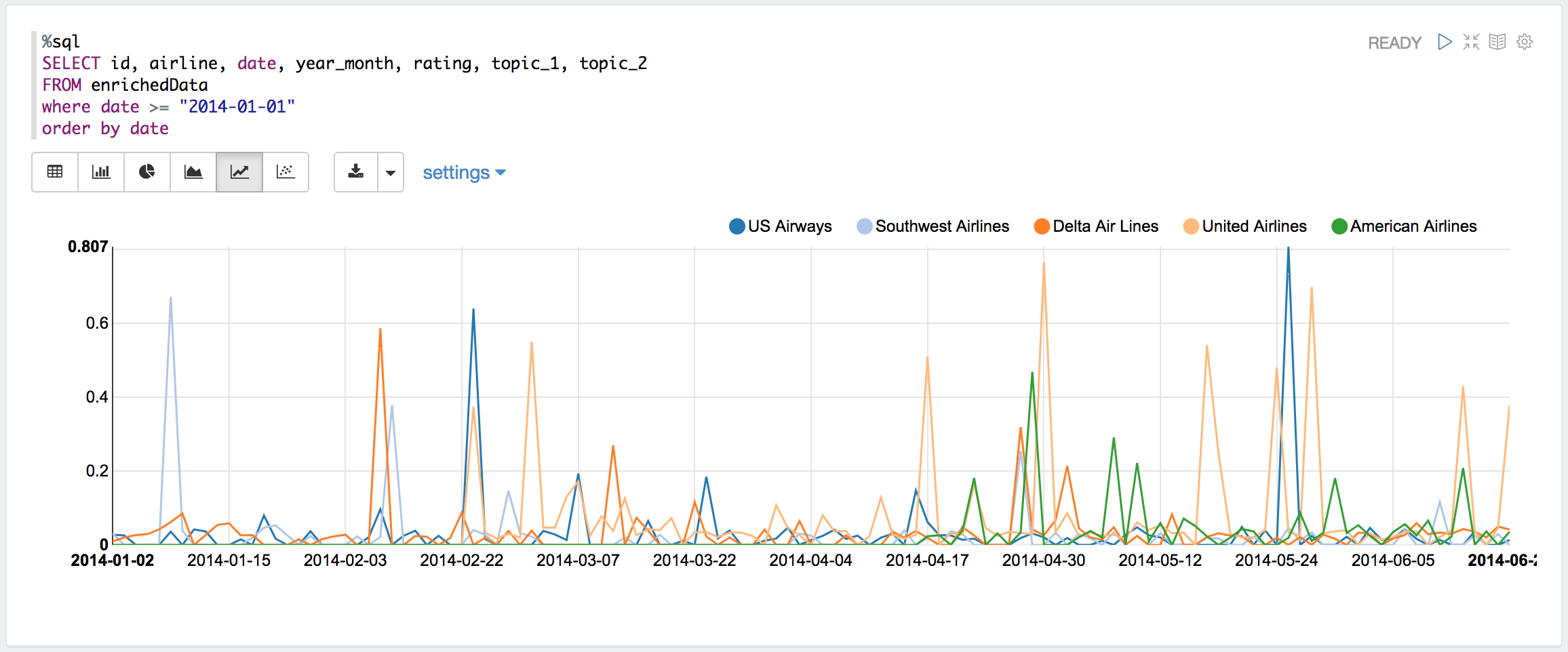
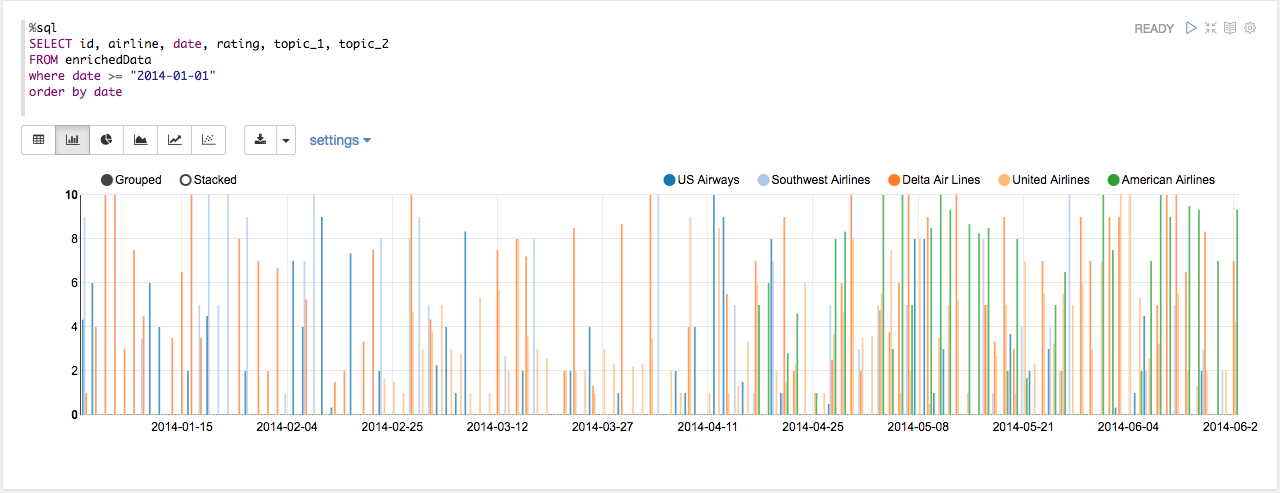
Average rating and airlines for each day
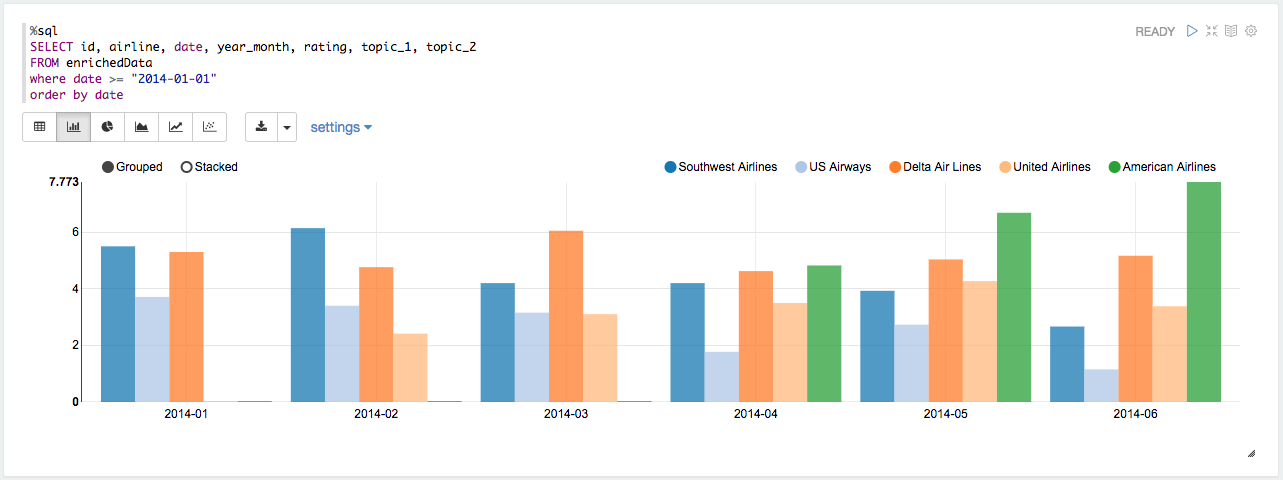
Average rating and airlines for each month
Topic 1 corresponding to time line
reviews (documents) relate to topic 1